
As large language models (LLMs) continue to advance in complexity and resource consumption, the demand for powerful, efficient and scalable hardware platforms has never been greater. Intel® Gaudi® 2 AI accelerator nodes have emerged as a strong contender in this space, promising high performance at scale. Recently, in collaboration with our longtime technology ally Intel, we tested the impact of running LLMs on Intel® Xeon® CPUs with the Intel® AMX AI accelerator and data showed it to be a cost-effective alternative for specific applications like chatbots and productivity tools.
Now, Presidio and Intel have teamed with Denvr Dataworks to explore the capabilities and impact of utilizing the Intel Gaudi 2 AI accelerator in LLM inference and Retrieval-Augmented Generation (RAG) pipeline creation while running on Denvr Cloud. We conducted a series of benchmarks using the Mistral Large 2 model to evaluate the performance of Intel Gaudi 2 technology under different levels of load.
The results were impressive, particularly in terms of delivering reliably high performance under load, scalability, and simplifying setup. In addition, testing showed several advantages from Denvr Cloud. Running large-scale LLM inferencing and RAG pipelines on the Intel Gaudi 2 AI accelerator addresses the need for cost-effective scaling, improving both throughput and latency for AI workloads. Intel Gaudi 2 technology provides optimized energy efficiency and supports high-concurrency inferencing, which is crucial for handling large models and real-time responses. It seamlessly integrates with popular frameworks, making deployment of generative AI (GenAI ) applications easier and more efficient.
We’d like to share insights into why we chose to test Intel Gaudi 2 technology on Denvr Cloud, break down our key findings and explain why Intel Gaudi 2 AI accelerators offer a compelling option for customers working with LLMs and RAG on Denvr Cloud. Lastly, we’ll provide detailed insight into how the test was conducted and the specific results that were achieved.
Why Test Intel Gaudi 2 AI Accelerator and Denvr Cloud?
Second-generation Intel Gaudi AI accelerators are co-designed by Intel and Habana Labs, an Intel company, specifically for deep learning workloads and AI inference, aiming to deliver optimal performance and scalability for AI tasks. It features Habana Processing Units (HPUs) with RoCE networking for low-latency communication, and high-bandwidth memory, making it a solid option for large-scale model deployments. Intel Gaudi 2 technology is supported by the Intel® SynapseAI software stack, which integrates seamlessly with popular frameworks like PyTorch, streamlining development and deployment for AI teams.
The primary appeal of using Intel Gaudi 2 AI accelerator nodes lies in their ability to handle large-scale model deployments with ease, making them an attractive option for enterprises and research institutions alike. This made Intel Gaudi 2 technology an ideal candidate for testing with one of the most demanding models: Mistral Large 2.
Denvr Dataworks offers a variety of cloud services designed to simplify and accelerate AI development, providing scalable access to advanced AI accelerators like the Intel Gaudi 2 product. Their flexible consumption model enables AI and machine learning (ML) workloads without the need for significant upfront capital investment.
Denvr Cloud’s advanced AI infrastructure – with Intel Gaudi 2 technology, supercomputer-level networking, and flexible cloud services optimized for AI workloads – includes on-demand and reserved compute. It supports key features like AI training, inference, and RAG-as-a-Service, alongside automation for deploying AI frameworks and foundational models. Denvr Cloud also provides tools for AI research and data processing with no access fees for data transfer, making it an attractive option for AI development and deployment.
Benchmarking: Mistral Large 2
We evaluated Mistral Large 2 for text generation on Intel Gaudi 2 nodes under varying batch sizes, loads and levels of concurrency. Our objective was to measure Intel Gaudi 2 technology performance, focusing on key metrics like throughput (tokens/second), time to first token (TTFT), and memory usage.
The benchmarks covered a range of concurrent requests – 500, 1,000, 4,000, and 10,000 – to assess how well the Intel Gaudi nodes handled:
- Simultaneous requests
- Token generation speed
- Memory management
The maximum input token size differed for each input based on the prompt size. It varied over a range of 1,024 to 4,096; the average output token size was 1,024. We expect our customers to be able to reproduce similar results with comparable volume of knowledge documents, chunk sizes, batch sizes, text prompts, and concurrency levels.
Our goal was to determine how well Intel Gaudi 2 technology optimizes an Inference-as-a-Service use case—an essential application for businesses looking to enhance their LLMs, especially for AI-driven tasks like RAG pipeline creation.
Performance Metrics and Results: Throughput, Latency and Memory Usage
Our benchmarks yielded the following results, summarized in Table 1 in the Appendix. Figure 4 below provides a chart representation of throughput (tokens/second), tokens per second per card, throughput per card, and time to first token at the different concurrency levels.
- Throughput:
- At 500 requests, throughput was 3,069 tokens/second, scaling up to 6,966 tokens/second at 10,000 requests. Intel Gaudi 2 technology demonstrated strong scalability, efficiently handling higher loads across all levels.
- Tokens per Second per Card:
- Each card processed 350-400 tokens/second at lower loads, increasing to 900-1,000 tokens/second at higher loads. This shows that the cards become more efficient under higher loads, though performance plateaued at around 1,000 tokens/second per card.
- Time to First Token:
- For 500 requests, the TTFT was 240ms, which is fast and ideal for interactive applications. However, at 10,000 requests, it increased to 3,400ms, indicating a significant rise in first token latency under heavier loads.
- While the first token latency (TTFT) increases significantly with heavier loads (from 240ms for 500 requests to 3,400ms for 10,000 requests), the system’s throughput scales well with higher concurrency. This suggests that although the initial token generation may be delayed under high traffic, the overall system performance remains balanced due to improved throughput. This can make the system more suitable for handling large volumes of requests efficiently, mitigating the impact of increased TTFT.
- 4. Memory Usage:
- Memory allocation grew with load, peaking at 82.49 GB at 10,000 requests. While memory remained efficient across most load levels, it approached maximum capacity at higher loads, emphasizing the importance of resource management under peak conditions.
Results by Load Level:
- 500 Requests:
- Low-latency, efficient memory usage and quick response times, making it suitable for interactive applications.
- 1,000 Requests:
- Noticeable increase in throughput with a slight rise in TTFT, though it remained under one second.
- 4,000 Requests:
- Higher throughput, moderate increase in TTFT and memory usage, indicating emerging latency limits.
- 10,000 Requests:
- Maximum throughput maintained, though the significant rise in TTFT and memory usage highlights the need for careful resource management at peak loads.
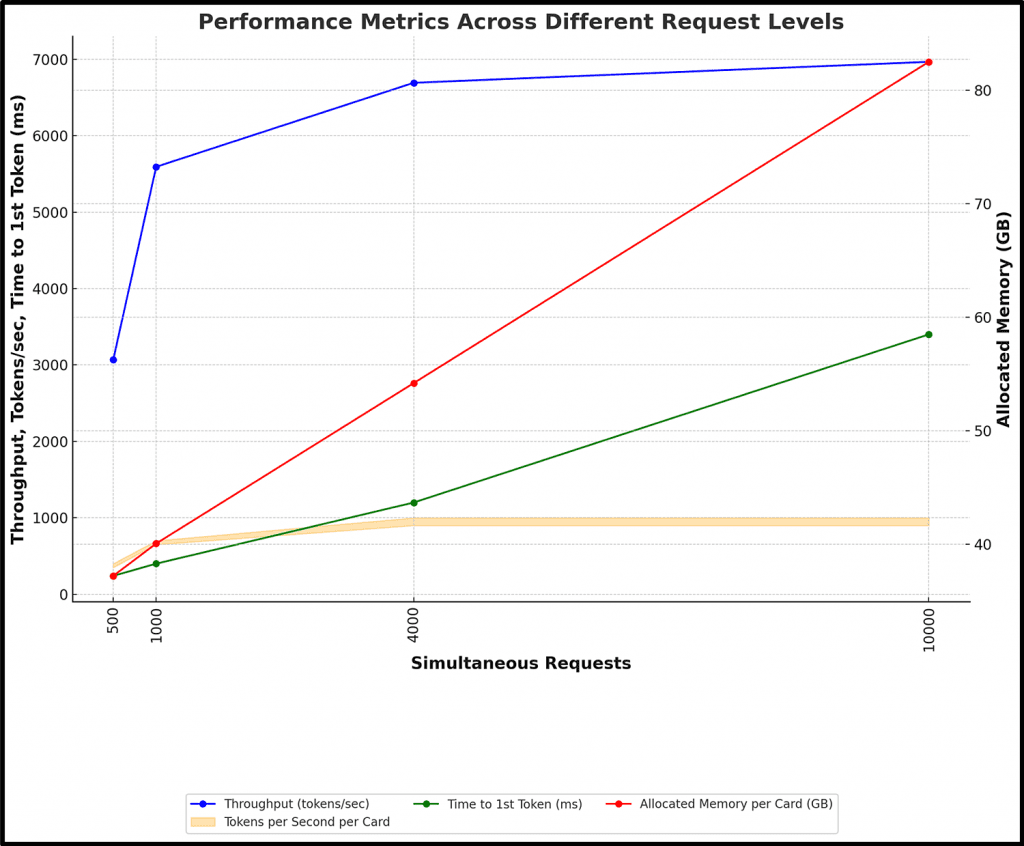
Figure 4. Test results graph.
Testing Reveals Key Advantages of Intel Gaudi 2 AI Accelerator
Based on our testing, several features of Intel Gaudi 2 nodes stood out:
- Scalability: The system scaled effectively in both single-node and multi-node configurations, making it ideal for large-scale deployments where handling increasing demand is critical.
- Consistent Performance: Even under higher loads, Intel Gaudi 2 AI accelerators maintained reliable performance with strong throughput and reasonable latency, especially at moderate levels of concurrent requests.
- Cost-Effectiveness: Intel Gaudi 2 nodes offer a cost-effective alternative to traditional GPUs, especially in large-scale deployments where lower energy consumption and high performance can result in significant savings over time.
- High Memory Bandwidth: Intel Gaudi nodes are designed with high memory bandwidth, which is critical for the fast processing of large datasets often used in LLM training and inference.
- Ease of Setup: Installing Intel Gaudi 2 product hardware was quick and straightforward, allowing models to be deployed with minimal configuration.
- Optimized Framework Support: With built-in support for PyTorch, integration into existing ML pipelines was smooth and efficient.
- Optimized for PyTorch: Intel Gaudi nodes come with optimized support for popular ML frameworks like PyTorch, enabling easier integration with existing ML pipelines.
Conclusion
Our test results show that the Intel Gaudi 2 AI accelerator is a strong option for developers deploying large-scale AI models. Its high performance, scalability, and ease of use make it particularly compelling for LLM inference and RAG pipelines, especially for those targeting efficient deep learning workloads.
Throughout our benchmarks, Intel Gaudi 2 technology handled high concurrent requests with impressive scalability, demonstrating its ability to efficiently manage AI-driven tasks like RAG pipeline creation. Even under heavier loads, it maintained reliable performance, with reasonable latency and effective memory usage.
Presidio regularly conducts tests like this to discover how new solutions from Intel and other ecosystem allies can deliver ever-greater results to solve customer challenges. We encourage AI developers to explore the capabilities of Intel Gaudi technology firsthand. With its scalable architecture, optimized software stack, and availability on Denvr Cloud, it provides a unique platform for testing deep learning workloads and LLM inference at scale.
Contact Presidio to learn more and start experimenting with the Intel Gaudi 2 AI accelerator on Denvr Cloud to see how it can speed your own LLM models and AI workloads.
Appendix: Details from the Testing and Results
Test Architecture:
The test architecture (Figure 1) begins with the Presidio Knowledge Base as the foundational data source, which feeds into the RAG Testing Pipeline, processing over 1,000 diverse inputs. These inputs simulate various user interactions or scenarios by generating 10 unique personas, creating a robust framework for testing. The personas then produce 10,000+ RAG prompts, rigorously testing the system’s capabilities.
At the core of the setup is the LLM middleware application, interfacing with powerful models like Mistral Large 2. This model is sharded across multiple nodes for inference. The middleware was designed to optimize the model performance on Intel Gaudi 2 AI accelerators on the Denvr Cloud platform, focusing on both hardware efficiency and advanced data management.
Our key performance metrics included throughput (tokens/second), time to first token (TTFT), and allocated memory usage, as these directly reflect the hardware performance. Model-specific metrics such as contextual recall, precision, relevancy, answer veracity, and security were secondary, with the primary being how well Intel Gaudi 2 technology supports LLM performance.
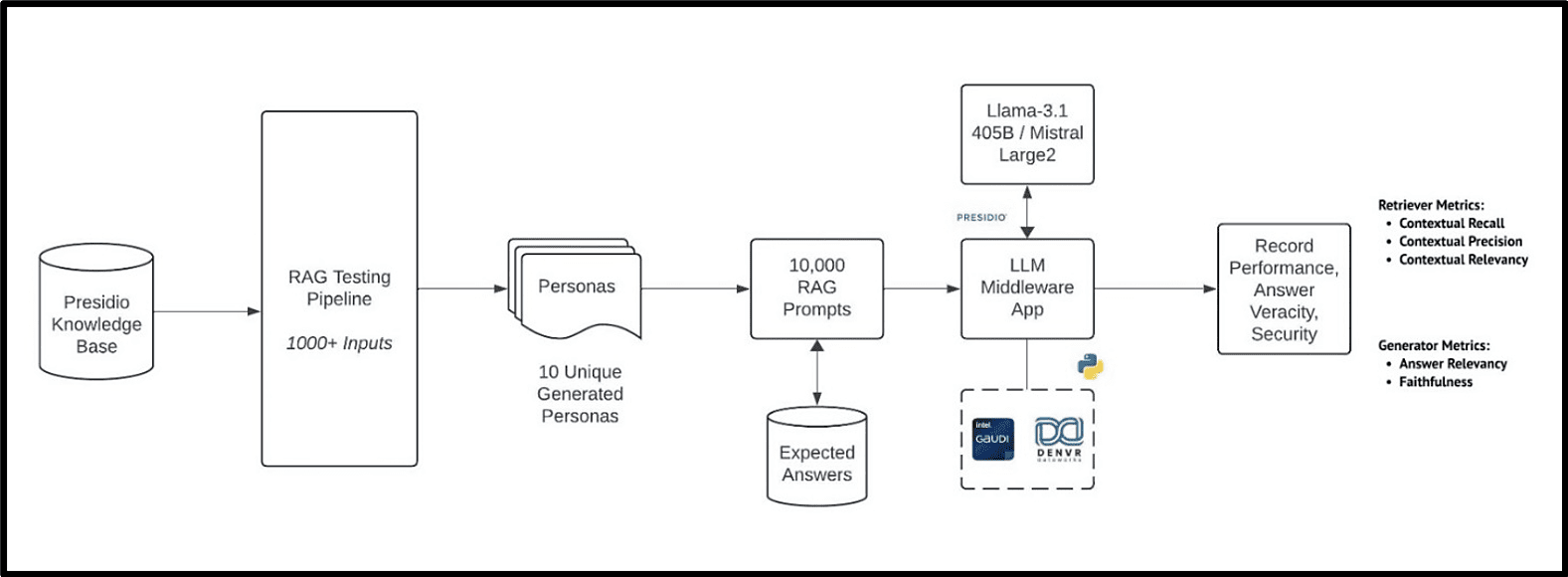
Figure 1. Intel Gaudi 2 AI accelerator LLM and RAG test architecture.
Intel Gaudi 2 Node Cluster on Denvr Cloud
The Intel Gaudi 2 node cluster on Denvr Cloud (Figure 2) consists of four Intel Gaudi 2 nodes, each connected via a high-throughput, low-latency RoCE v2 Ethernet network, ensuring efficient AI traffic communication between nodes. These nodes are linked to high-performance storage, providing fast access to data for AI workloads. The architecture is optimized for Machine Learning (ML) and AI inference tasks, leveraging Intel Gaudi 2 technology’s compute power, RoCE low-latency networking, and robust storage.
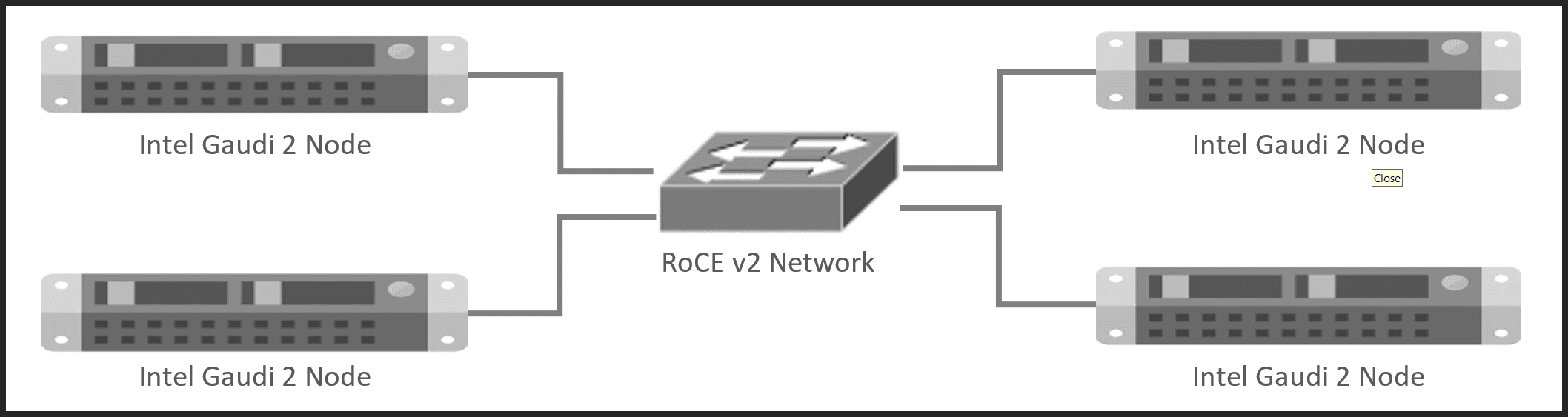
Figure 2: Intel Gaudi 2 node cluster on Denvr Cloud network configuration
Each Intel Gaudi 2 node (Figure 3) is built on a dual-socket Intel® Xeon® Platinum 8380 processor-based server with 80 cores and 1TB RAM. The node includes eight Intel Gaudi 2 AI processor cards. Each card delivers up to 432 TFLOPS of peak performance for BF16, and 865 TFLOPS of peak performance for FP8 (Reference). Each Gaudi processor card has 96GB of HBM2e memory, providing 2.45 TB/s of bandwidth. The node is connected via 24x 100Gbps RoCE v2 Ethernet ports for high-speed networking and is deployed in a rack-mounted configuration. The Denvr Cloud infrastructure supports this setup, offering both direct-attached NVMe and RoCE networking to ensure seamless data communication between nodes and networked storage.
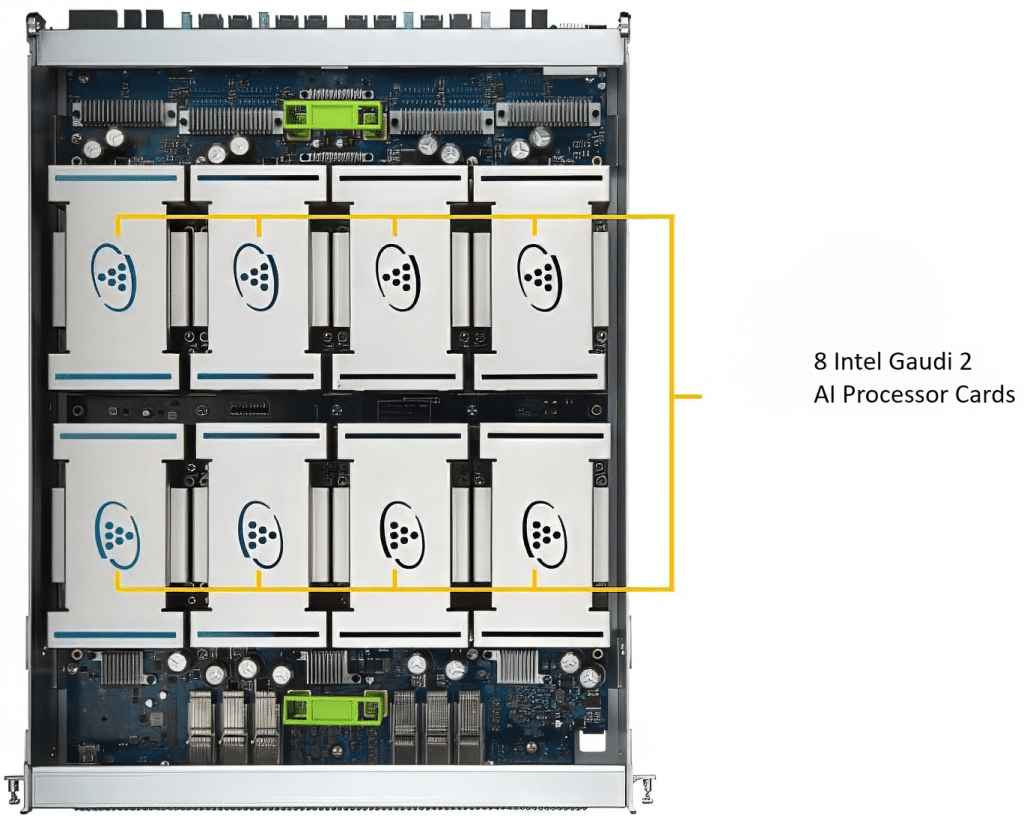
Figure 3. Intel Gaudi node with 8 Intel Gaudi 2 AI processor cards.
Software Components
For LLM inference on Intel Gaudi 2, several key software components work together to optimize performance.
- SynapseAI: The core software stack from Intel Habana Labs, providing tools and libraries optimized for Intel Gaudi 2 product hardware.
- Optimum Habana: Integrated with Hugging Face, enabling seamless use of Intel Gaudi accelerators for deep learning tasks.
- Ray: A distributed computing framework that scales workloads across multiple nodes.
- DeepSpeed: A deep learning optimization library that enhances inference with large models.
- Docker: Provides containerization, ensuring isolated and consistent deployment of all necessary components.
Together, these tools create an optimized environment for running LLM inference workloads on Intel Gaudi 2 technology.
Review of Results by Load Level
Table 1. Test Results at a Glance.
| Requests | Tokens/sec (Per Card) | Time to First Token (TTFT) | Throughput (Tokens/sec) | Memory Usage per Card |
| 500 | 350-400 | ~240ms | 3,069.06 | Allocated: 37.22 GB, Max: 45.24 GB, Available: 94.62 GB |
| 1,000 | 650-700 | ~400ms | 5,592.99 | Allocated: 40.07 GB, Max: 64.5 GB, Available: 94.62 GB |
| 4,000 | 900-1,000 | ~1,200ms | 6,692.65 | Allocated: 54.2 GB, Max: 94.56 GB, Available: 94.62 GB |
| 10,000 | 900-1,000 | ~3,400ms | 6,966.64 | Allocated: 82.49 GB, Max: 94.61 GB, Available: 94.62 GB |
