
Change data capture (CDC) refers to the process of identifying and capturing changes made to data in a database and then delivering those changes in near real-time to a downstream process or system. Dynamic tables in Snowflake can implement CDC, leveraging their flexibility and near real-time capabilities to capture and process data changes seamlessly.
Snowflake Dynamic Tables
When we talk about dynamic tables, we usually mean schemas or tables that are created, altered, or maintained using Snowflake’s SQL capabilities programmatically or in response to runtime conditions. Because Snowflake supports dynamic SQL and can handle schema changes and data transformations well, it is strongly tied to the idea of dynamic tables.
Dynamic tables in Snowflake provide a flexible way to manage schema evolution and adapt to changing data structures without the need for extensive schema modifications. This flexibility is important for implementing CDC because it lets tables change to meet the needs of the business while still capturing and processing data efficiently.
Dynamic Tables can join and aggregate across multiple source objects and incrementally update results as sources change. LAG specifies the difference in time between the dynamic table and the base table that forms its foundation. Snowflake not only automatically optimizes queries to make them more efficient and reduce the need for human tuning, but it also keeps compute resources and storage separate. This way, scalable compute resources can handle data without affecting the scalability of storage.
With the help of all these characteristics, businesses can adopt a “Zero ETL” strategy.
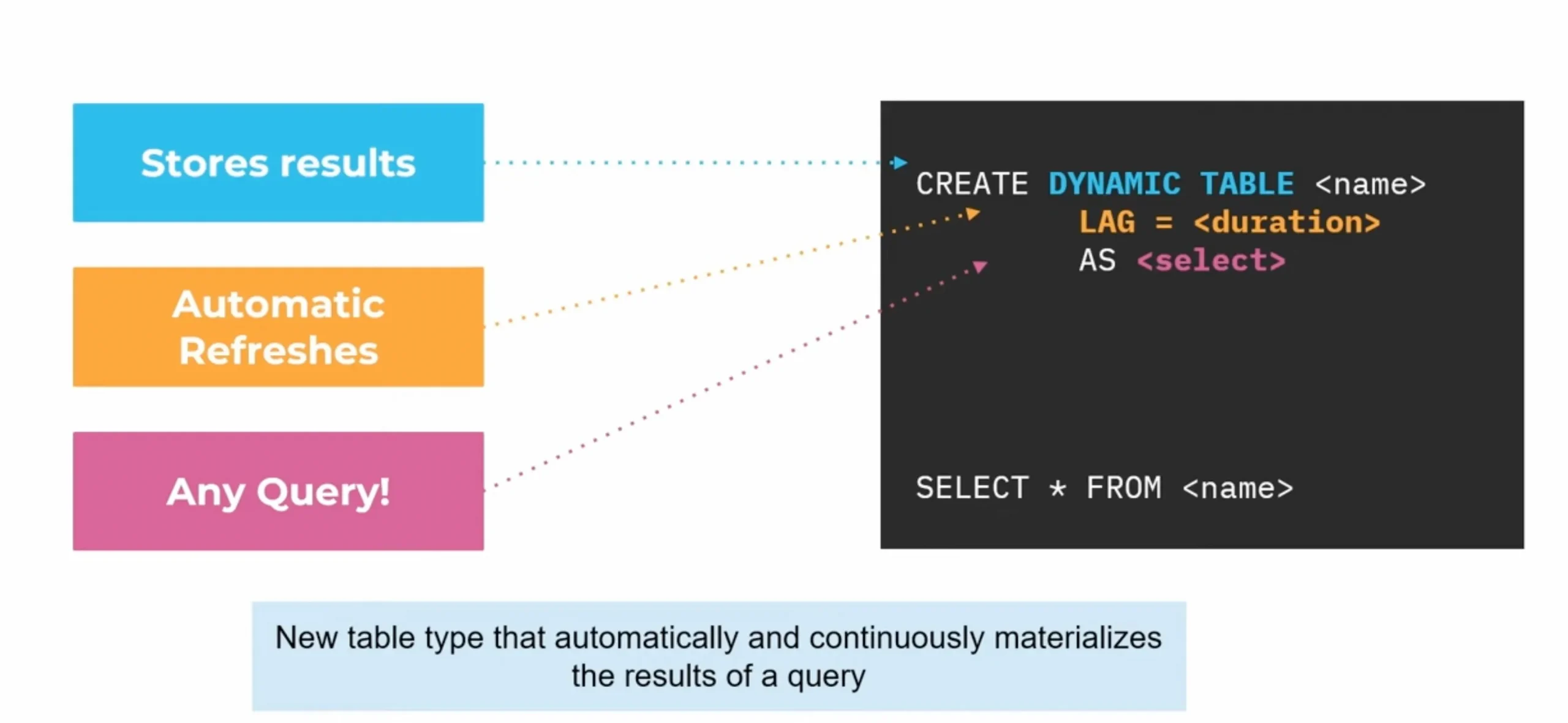
Key Features of Dynamic Tables for CDC
Schema Evolution:
Schema evolution is vital to preserving continuity and data integrity in CDC scenarios. Schema evolution in Snowflake dynamic tables makes it easy to quickly upgrade and change schemas by allowing agile development and data modeling techniques. It also cuts down on manual schema updates that are prone to mistakes, which helps make the best use of resources.
Real-time Data Capture:
In the past, keeping streaming and batch architectures separate has been hard for streaming data because it meant managing two systems at once, which added extra work and made failures more likely.
The integration of batch and streaming data increases delay and complexity in pipelining.
Many users can stream without knowing how to use Spark, Flink, or other streaming systems. This is possible with dynamic tables, which let users use common SQL and strong stream processing features. Furthermore, dynamic tables eliminate the extra logic often required for incremental updates by automatically applying incremental updates for both batch and streaming data.
Data Vault:
Data vault modeling is a hybrid approach that combines traditional relational data warehouse models with newer big data architectures to build a data warehouse for enterprise-scale analytics. Dynamic tables function as materialized views, adapting dynamically to the data they support, making them an ideal fit for the information mart layer in a Data Vault Architecture.
Implementing CDC using Dynamic Tables
A dynamic table allows us to specify a query, and the result materializes. It can track changes made to the query data we give it. It slowly updates the materialized results, solving declarative data transformation problems.
One key feature of this table that differentiates it from features like streams and tasks is that it eliminates the additional step. This step involves identifying and merging changes from the base table. The entire process is automatically performed within the dynamic table.
So, with this feature there is no longer a need to write code to transform and update the data in a separate target table. Dynamic tables support both incremental changes and Slowly Changing Dimensions (SCD) with row versioning.
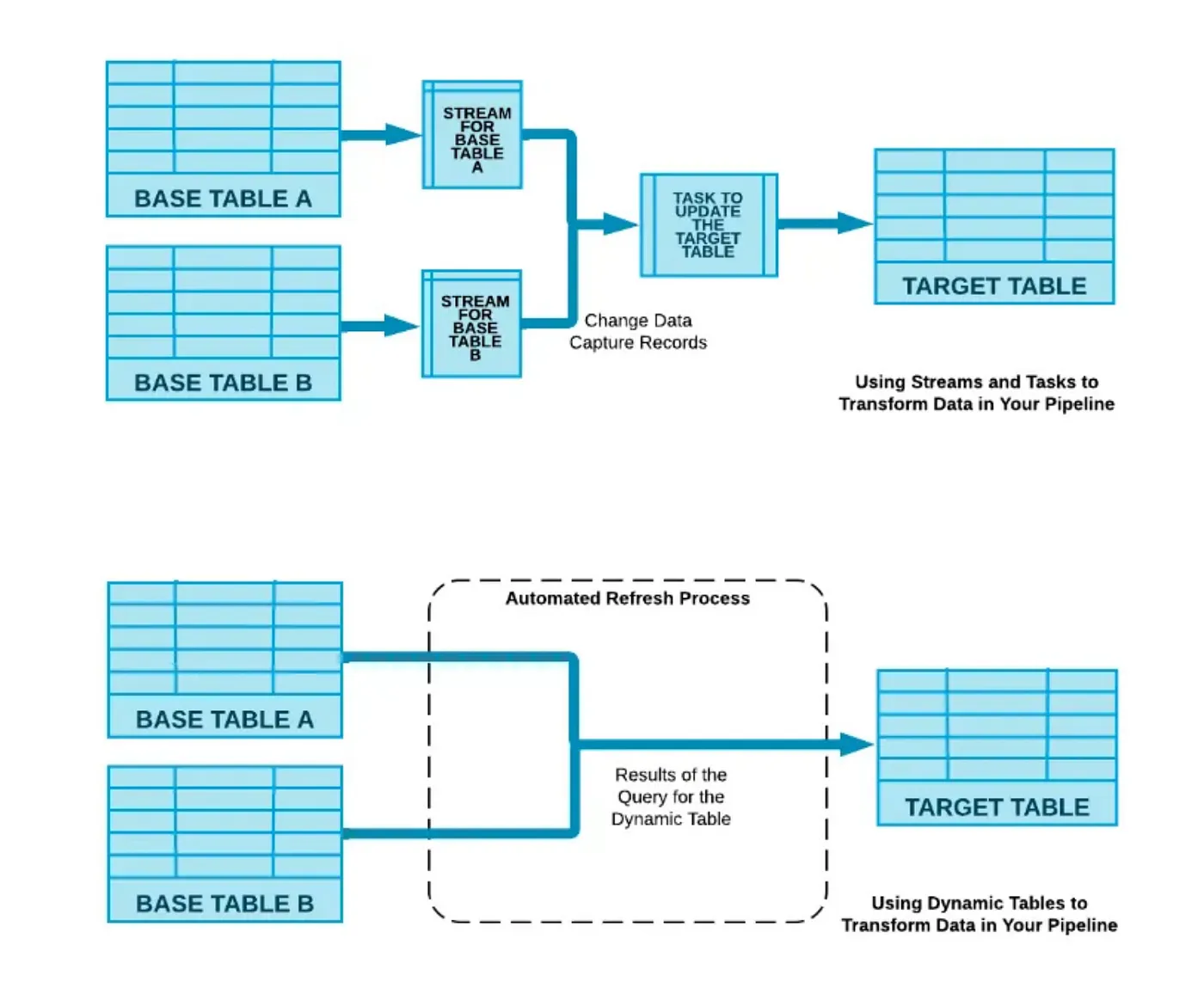 Implementation of incremental changes:
Implementation of incremental changes:
Step 1—Setup Warehouse, DB, Schema
USE ROLE accountadmin; CREATE OR replace WAREHOUSE demo_wh warehouse_size = 'XSMALL'; USE WAREHOUSE demo_wh CREATE OR replace DATABASE demo_db; CREATE OR replace SCHEMA demo_schema;
Step 2—Create raw table
CREATE OR REPLACE TABLE demo_db.demo_schema.orders_raw AS SELECT * FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS LIMIT 100;
Step 3—Create a dynamic table
CREATE OR REPLACE DYNAMIC TABLE demo_db.demo_schema.orders TARGET_LAG = '1 minute' WAREHOUSE = demo_wh AS SELECT * FROM demo_db.demo_schema.orders_raw;
Step 4—Modify raw table
SELECT * FROM demo_db.demo_schema.orders WHERE O_CUSTKEY = 106660

UPDATE demo_db.demo_schema.orders_raw SET O_TOTALPRICE = 135445.43 WHERE O_CUSTKEY = 106660
Step 5—Check the CDC data reflection in the dynamic table.
SELECT * FROM demo_db.demo_schema.orders WHERE O_CUSTKEY = 106660

Implementation of SCD2 with row versioning:
Step 1—Create raw table
CREATE OR REPLACE TABLE demo_db.demo_schema.inventory_raw AS SELECT * FROM SNOWFLAKE_SAMPLE_DATA.TPCDS_SF10TCL.INVENTORY limit 100;
Step 2: Create a stage table.
CREATE OR REPLACE TABLE demo_db.demo_schema.inventory_stg AS SELECT * FROM demo_db.demo_schema.inventory_raw;
Step 3—Create a dynamic table
CREATE OR REPLACE DYNAMIC TABLE demo_db.demo_schema.inventory_main TARGET_LAG = '1 minute' WAREHOUSE = demo_wh AS SELECT INV_DATE_SK ,INV_ITEM_SK,INV_WAREHOUSE_SK,INV_QUANTITY_ON_HAND, ROW_NUMBER () OVER (PARTITION BY INV_ITEM_SK ORDER BY INV_DATE_SK DESC) rnm, CASE WHEN rnm=1 THEN 'Y' ELSE 'N' END ACTION_CD, CASE WHEN rnm=1 THEN NULL ELSE CURRENT_DATE () END LOAD_END_DATE FROM demo_db.demo_schema.inventory_stg
Step 4—Modify Stage Table
SELECT * FROM demo_db.demo_schema.inventory_stg WHERE INV_ITEM_SK= 386545
INSERT INTO demo_db.demo_schema.inventory_stg VALUES (2451060, 386545,2,999) SELECT * FROM demo_db.demo_schema.inventory_stg WHERE INV_ITEM_SK= 386545.

Step 5—Refresh Dynamic Table
ALTER DYNAMIC TABLE demo_db.demo_schema.inventory_main REFRESH
Step 6—Check SCD reflection in the dynamic table
SELECT * FROM demo_db.demo_schema.inventory_main WHERE INV_ITEM_SK=386545

Managing Dynamic Tables Refresh
Incremental refresh:
When possible, the automated refresh process performs an incremental refresh. With incremental refresh, the automated refresh process analyzes the query for the dynamic table. It computes the changes to the query results (the changes since the dynamic table was last refreshed). The refresh process then merges those changes into the dynamic table.
Full refresh:
If the automated process is unable to determine how to perform an incremental refresh, the process performs a full refresh. With a full refresh, the automated refresh process performs the query for the dynamic table and materializes the results. This completely replaces the current materialized results of the dynamic table.
Conclusion
Dynamic tables possess immense capabilities for solving various use cases. They improve operational efficiency, availability, and CDC management. The goal of this blog was to provide an overview of dynamic tables along with several use case examples.
