
In modern data-driven applications, businesses need a way to track and process database changes in real time. Traditional batch processing methods are often inefficient and introduce latency. Change Data Capture (CDC) provides a solution by capturing incremental changes in a database and streaming them for further processing. This setup enables real-time analytics, data synchronization across multiple systems, and efficient event-driven architectures.
In this guide, we’ll walk through the steps to set up CDC for a MySQL database hosted on AWS RDS, use AWS Database Migration Service (DMS) to stream changes to Amazon Kinesis, further process this data using AWS Glue, and analyze it using AWS Athena.

Prerequisites
Before diving into the setup, ensure you have:
- An AWS account.
- A MySQL RDS instance with appropriate permissions.
- Amazon Kinesis, AWS DMS, and AWS Glue access.
- A Delta Lake-compatible storage location (e.g., S3).
Step 1: Enable Binary Logging on RDS
To capture database changes in real time, we need to enable binary logging on MySQL RDS. Binary logs record all changes to the database and make them available for replication. Without binary logging, AWS DMS cannot capture and stream changes efficiently.
Before we begin streaming changes, we must configure the RDS instance to log all modifications at the row level. This ensures that every update, insert, or delete operation is accurately captured.
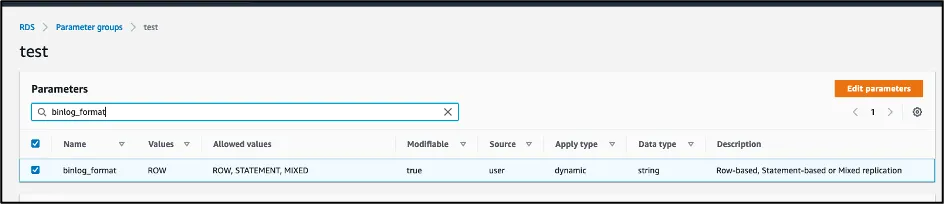
Configure Binary Log Parameters:
- In the RDS parameter group, set the following parameters:
-
binlog_format = ROW(mandatory)
-
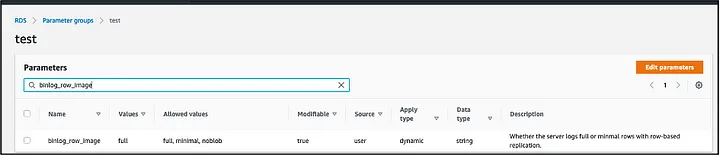
binlog_row_image = FULL(optional but recommended for full row data). Enabling binlog_row_image = FULL ensures that all events generated by the CDC code contain the database image before and after the change. For example, if a row contains the column table.a = 10 and the update sets the column table.a = 20, the binary log and Kinesis event will contain table.a = 10 as the before image and table.a = 20 as the after image.
Apply Parameter Group and Reboot:
- Associate the parameter group with the RDS instance.
- Reboot the instance for changes to take effect.
- You can verify these parameters from the database using a MySQL client:
SELECT @@binlog_row_image AS binlog_row_image; +------------------+ | binlog_row_image | +------------------+ | FULL | +------------------+ SELECT @@binlog_format AS binlog_format; +---------------+ | binlog_format | +---------------+ | ROW | +---------------+ Create a Database User for Replication: Execute the following SQL commands to create a user and grant necessary roles:
CREATE USER 'repl'@'%' IDENTIFIED BY 'slavepass'; GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT ON *.* TO 'repl'@'%';Set Binary Log Retention: Verify and configure binary log retention to ensure sufficient time for CDC processing:
CALL mysql.rds_show_configuration; CALL mysql.rds_set_configuration("binlog retention hours", 24);Step 2: Create a Kinesis Stream
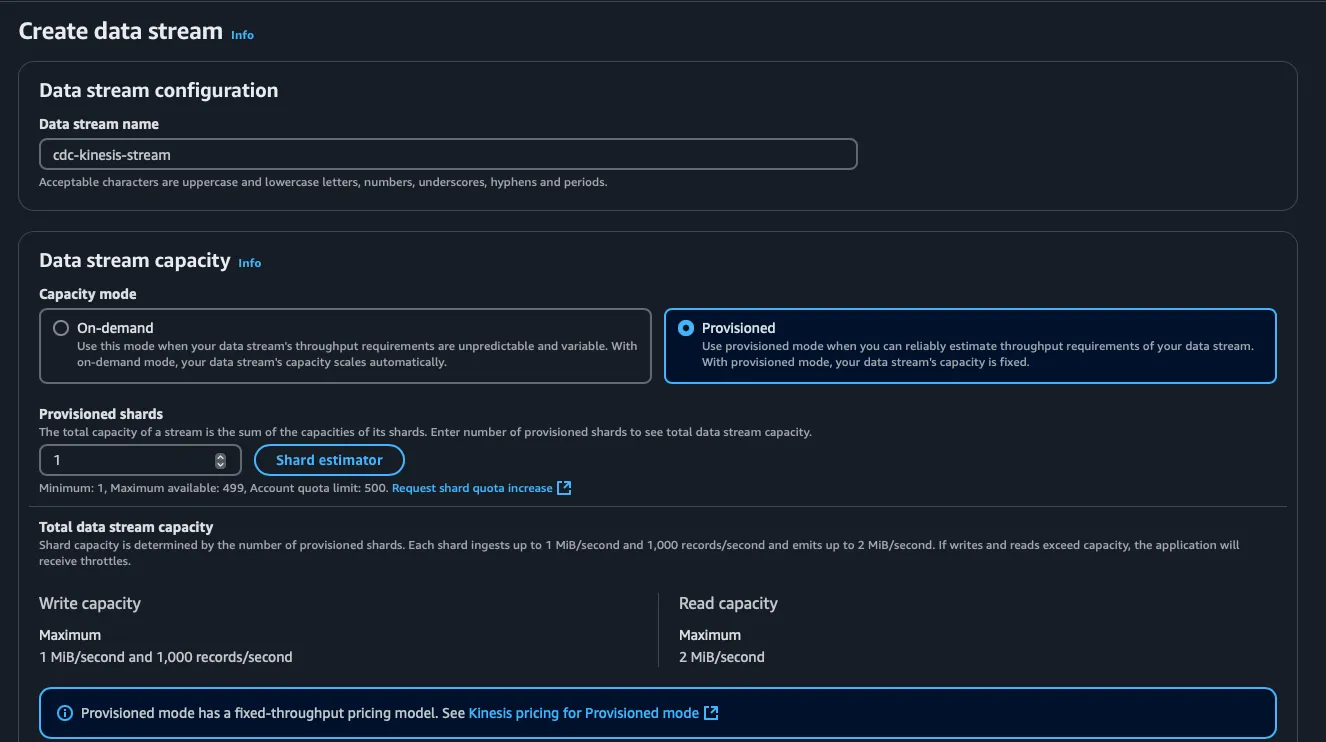
With binary logging enabled, the next step is to create an Amazon Kinesis stream to capture and process the changes in real time. Kinesis acts as a highly scalable data pipeline that allows us to stream and analyze data efficiently.
Based on your requirements, create a Kinesis Data Stream:
- Use on-demand mode for automatic scaling.
- Use provisioned mode for precise resource control.
By integrating Kinesis, we ensure that every database change is captured and made available for downstream processing without delay.
Step 3: AWS DMS Setup
Now that we have our MySQL source and Kinesis stream ready, AWS Database Migration Service (DMS) is required to handle real-time replication. DMS continuously extracts changes from the MySQL database and streams them to Kinesis.
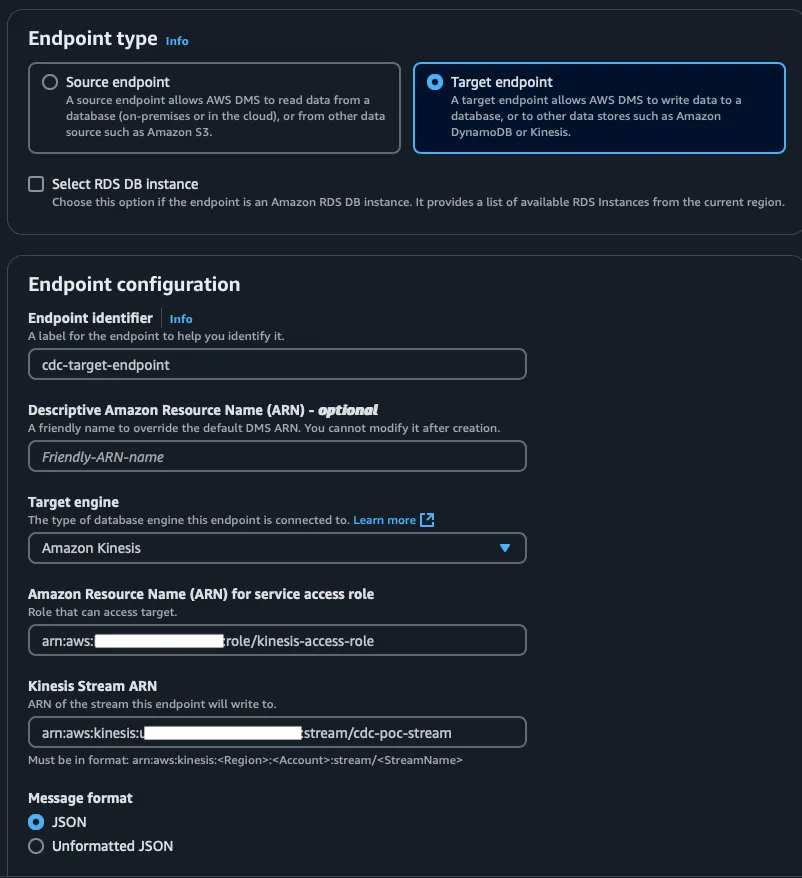
To allow AWS DMS to connect to our data sources, we need to define endpoints:
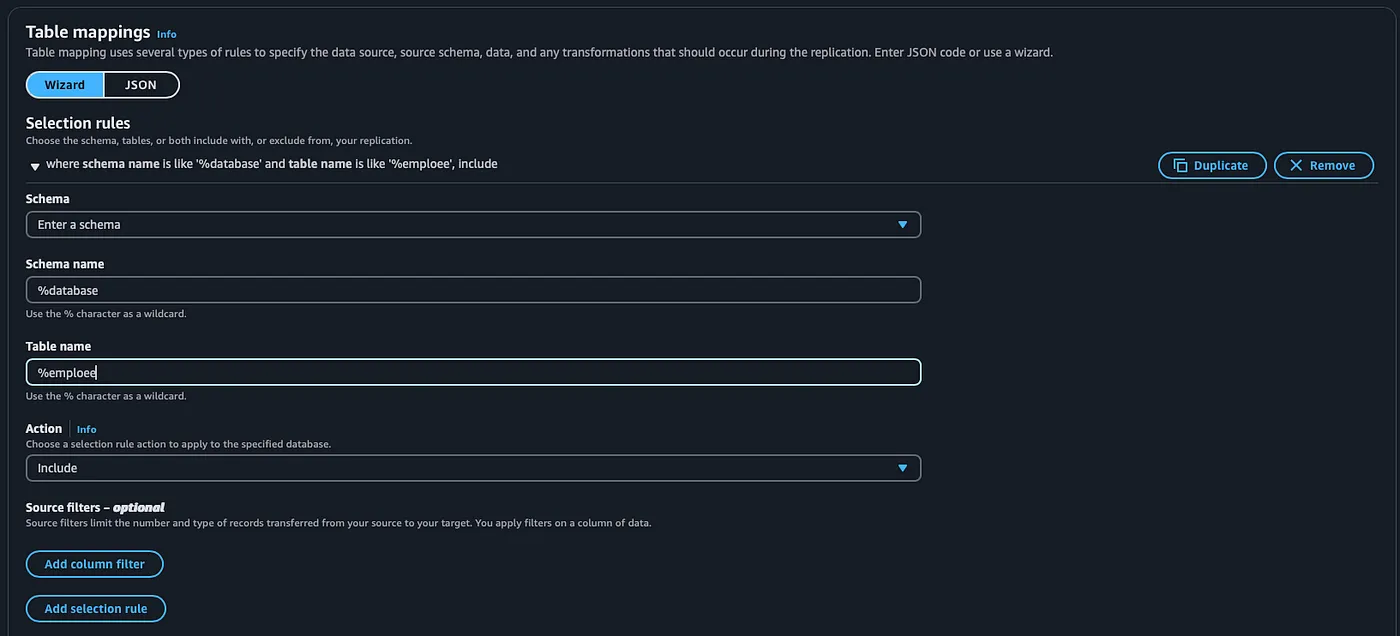
Create Endpoints
- Source Endpoint: Specify the MySQL engine and credentials (use AWS Secrets Manager for secure credentials storage).

- Target Endpoint: Specify Kinesis as the target and provide the ARN of the stream. Ensure the endpoint role has appropriate policies to access Kinesis.
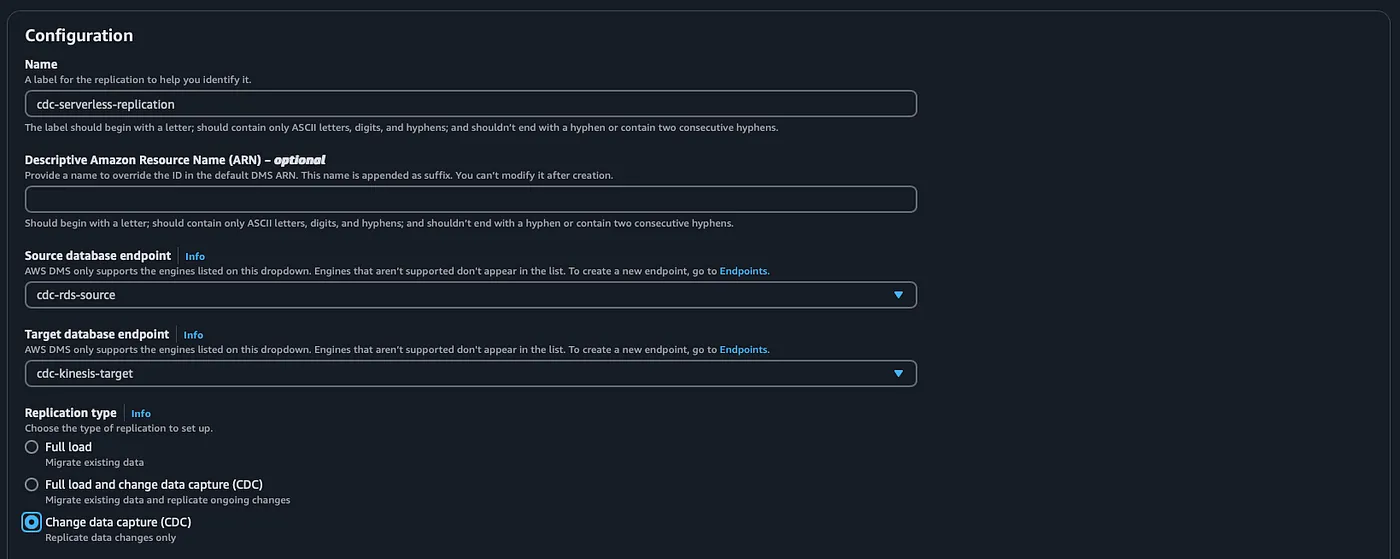
Step 4: Serverless Replication (Preferable for CDC)
For a fully serverless setup, AWS provides serverless replication instances with built-in CDC (Change Data Capture) capabilities, simplifying infrastructure management while ensuring scalability.
Prerequisites
Create VPC endpoints for both the RDS source and Kinesis target.
- Example service names:
- For RDS:
com.amazonaws.<region>.rds
- For Kinesis:
com.amazonaws.<region>.kinesis
Attach a security group to permit traffic within the VPC CIDR block. Also, associate the aforementioned security group with the RDS security group.
Serverless Replication Instance Setup
- Select source and target endpoints.
- Choose replication type as CDC.
- Configure instance settings (e.g., capacity and multi-AZ).
- Create a new subnet group under DMS, attach it, and assign the endpoint’s security group.
- Verify that all components (RDS, Kinesis) are within the same VPC or connected.


Optional:
While serverless replication is recommended, some use cases may require a manually provisioned replication instance. This method provides greater control over resources and performance tuning.
Set Up a Replication Instance
- Choose an appropriate instance class (single or multi-AZ).
- Configure storage allocation based on your workload.
- Create a subnet group for DMS using the subnets in your VPC.
- Configure security groups to allow access to RDS and Kinesis.
- Test the connection between the source and target endpoints.
Create a Migration Task
- Use the replication instance, source endpoint, and target endpoint created earlier.
- Choose the “migrate and replicate” option.
- Adjust task settings as needed or leave them as default.
- Specify the database and table schema to capture changes.
- Disable premigration assessment.
- Enable automatic start and create the task.
AWS DMS will begin streaming changes from RDS to Kinesis in real time.
Step 5: Process Data Using AWS Glue and Load It as a Delta Table
With changes now flowing into Kinesis, efficiently processing and storing this real-time data is crucial for analytics and decision-making.
AWS Glue Streaming provides a scalable, serverless solution to process streaming data from Kinesis in real time, enabling seamless ingestion, transformation, cleaning, and storage in a Delta Lake table.
This ensures structured, queryable, and ACID-compliant data, optimized for real-time analytics.
AWS Glue Setup
Create a Glue Streaming Job:
- Use either Spark scripts or Visual ETL.
- Specify the Kinesis stream ARN as the source.
Job Configuration:
- Choose Spark streaming with the required configurations.
- Provide a role for Glue with access to Kinesis, S3, and CloudWatch Logs.
- Use the Delta Lake connector for Glue (ensure the Delta Lake library is included in the job configuration).

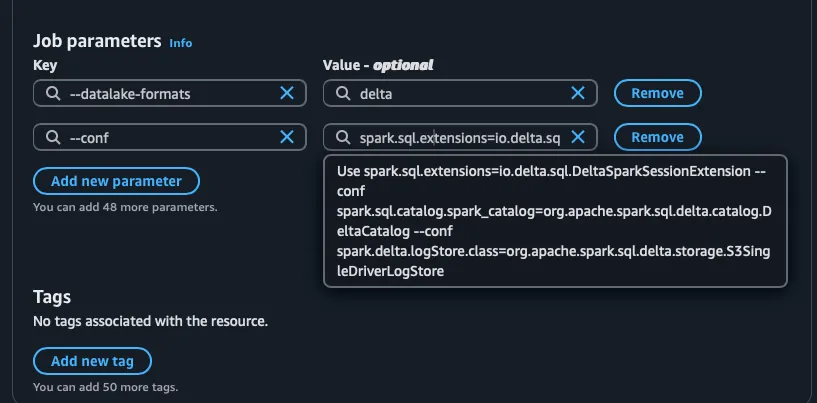
Prerequisite for AWS Glue (Initialize Delta Table if Necessary)
Ensure the Delta table exists at the desired location for streaming data. If not, initialize it with the following logic:
# Function to initialize Delta table if it doesn't exist def initialize_delta_table(): if not DeltaTable.isDeltaTable(spark, delta_table_path): # Create a dummy DataFrame to initialize the table dummy_data = [(0, "FirstName","LastName", "email@example.com" ,"2024-01-01", 0.0)] columns = ["employee_id","first_name", "last_name","email", "hire_date", "salary"] dummy_df = (spark.createDataFrame(dummy_data, columns) .withColumn("effective_start", lit(current_timestamp()).cast(TimestampType())) .withColumn("effective_end", lit(current_timestamp()).cast(TimestampType())) .withColumn("is_current", lit(False)) .withColumn("is_deleted", lit(False)) ) # Write as Delta table #choose the partition columns based on your need dummy_df.write.format("delta").partitionBy("hire_date","is_current").save(delta_table_path) # Call the function to initialize the table before streaming starts initialize_delta_table()
SCD Type 2 Implementation : Write Data to Delta Lake:
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job from delta.tables import DeltaTable import time from pyspark.sql.functions import ( col, from_json, struct, to_json, lit, current_timestamp, expr, ) from pyspark.sql.types import ( StructType, StructField, StringType, IntegerType, FloatType, TimestampType, ) ## @params: [JOB_NAME] args = getResolvedOptions(sys.argv, ["JOB_NAME"]) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args["JOB_NAME"], args) # Define the schema for the incoming data data_schema = StructType( [ StructField( "data", StructType( [ StructField("employee_id", IntegerType(), True), StructField("first_name", StringType(), True), StructField("last_name", StringType(), True), StructField("email", StringType(), True), StructField("hire_date", StringType(), True), StructField("salary", FloatType(), True), ] ), True, ), StructField( "metadata", StructType( [ StructField("record-type", StringType(), True), StructField("transaction-id", StringType(), True), StructField("schema-name", StringType(), True), StructField("partition-key-type", StringType(), True), StructField("table-name", StringType(), True), StructField("operation", StringType(), True), StructField("timestamp", TimestampType(), True), ] ), True, ), ] ) stream_name = "cdc-poc-stream" region = "us-east-1" checkpoint_location = "s3:///checkpoints/" delta_table_path = "s3:///employee" # Read data from Kinesis df = ( spark.readStream.format("kinesis") .option("streamName", stream_name) .option("region", region) .option("startingPosition", "LATEST") .load() .select(from_json(col("data").cast("string"), data_schema).alias("parsed_data")) ) # Extract data and metadata columns data_df = df.select( col("parsed_data.data.*"), col("parsed_data.metadata.operation"), col("parsed_data.metadata.timestamp"), ) # Function to handle SCD Type 2 operations with is_current and is_deleted def process_scd_type_2(batch_df, batch_id): delta_table = DeltaTable.forPath(spark, delta_table_path) # Mark existing rows as expired and set is_current to False updates_df = batch_df.filter(col("operation").isin(["insert", "update"])).drop( "operation" ) expired_ids = updates_df.select("employee_id").distinct() delta_table.alias("target").merge( expired_ids.alias("updates"), "target.employee_id = updates.employee_id AND target.effective_end IS NULL AND target.is_current = true", ).whenMatchedUpdate( set={"effective_end": current_timestamp(), "is_current": lit(False)} ).execute() # Insert new rows with is_current = True new_rows_df = updates_df.withColumn( "effective_start", lit(current_timestamp()).cast(TimestampType()) ) new_rows_df = new_rows_df.withColumn( "effective_end", lit(None).cast(TimestampType()) ) new_rows_df = new_rows_df.withColumn("is_current", lit(True)).withColumn( "is_deleted", lit(False) ) delta_table.alias("target").merge( new_rows_df.alias("source"), "target.employee_id = source.employee_id AND target.is_current = true", ).whenNotMatchedInsertAll().execute() # Handle delete operations by setting is_deleted to True and is_current to False delete_df = batch_df.filter(col("operation") == "delete").drop("operation") if not delete_df.isEmpty(): delete_ids = delete_df.select("employee_id").distinct() delta_table.alias("target").merge( delete_ids.alias("deletes"), "target.employee_id = deletes.employee_id AND target.is_current = true", ).whenMatchedUpdate( set={ "effective_end": current_timestamp(), "is_current": lit(False), "is_deleted": lit(True), } ).execute() # Write data to Delta table query = ( data_df.writeStream.foreachBatch( process_scd_type_2 ) # ForeachBatch handles the streaming operations .option("checkpointLocation", checkpoint_location) .start(delta_table_path) ) query.awaitTermination() job.commit()
Step 6: Register the Delta Table in the AWS Glue Catalog and Query using Athena
After creating the Delta table and streaming data into it, registering the table in the AWS Glue Catalog allows for easy management and discovery of its metadata.
This enables seamless querying through Amazon Athena, allowing you to run SQL queries on the real-time data without managing infrastructure, providing an efficient and scalable solution for analytics.
Register the Delta Table in AWS Glue Catalog
Create the table manually using Athena:
- Open the Amazon Athena Console.
- Navigate to the query editor and select the appropriate Glue database.
- Use the following SQL statement to create an external table that points to your Delta table’s location in S3:
CREATE EXTERNAL TABLE deltadatabase.employee LOCATION 'delta-table-location' TBLPROPERTIES ( 'table_type' = 'DELTA' );
Verify Table Creation:
- After executing the query, verify that the table is listed under the specified database in the Athena console.
Run SQL Queries:
- Use the Athena query editor to query the table. For example:
SELECT * FROM deltadatabase.employee; -- Fetch Active Records SELECT * FROM deltadatabase.employee WHERE is_current = true;
Optional: Connect with Amazon QuickSight
You can connect the Athena table to Amazon QuickSight for data visualization. Simply add Athena as a data source in QuickSight, select the table, and build interactive dashboards for real-time insights.
Conclusion
Change Data Capture (CDC) is a crucial technique for capturing and tracking real-time changes in data, enabling modern data pipeline builds. This guide outlines the steps to set up CDC for a MySQL database hosted on AWS RDS using AWS Database Migration Service (DMS) to stream changes to Amazon Kinesis. The process involves enabling binary logging on RDS, setting up a Kinesis stream, configuring AWS DMS endpoints, and creating a replication task.
For further processing, AWS Glue allows you to transform and store this data into a Delta Lake table, which can then be registered in the AWS Glue Catalog and queried using Amazon Athena. Optionally, you can visualize the data using Amazon QuickSight for more profound insights. This setup ensures efficient real-time data processing, enabling powerful analytics and decision-making capabilities.
