
Introduction:
In this blog post, we will delve into a prevalent issue encountered by AWS QuickSight users: the unexpected deletion of data sources has affected the visual information on the dashboard. AWS QuickSight offers a robust and intuitive platform for data visualization, yet deleting data sources can pose challenges. We will investigate the root causes of this problem and provide effective solutions.
What is Amazon QuickSight?
Amazon QuickSight is a fast cloud-powered BI service that makes it easy to build visualization, perform ad hoc analysis, and quickly get business insights from your data.
It allows you to easily create and publish interactive dashboards that include machine learning insights.
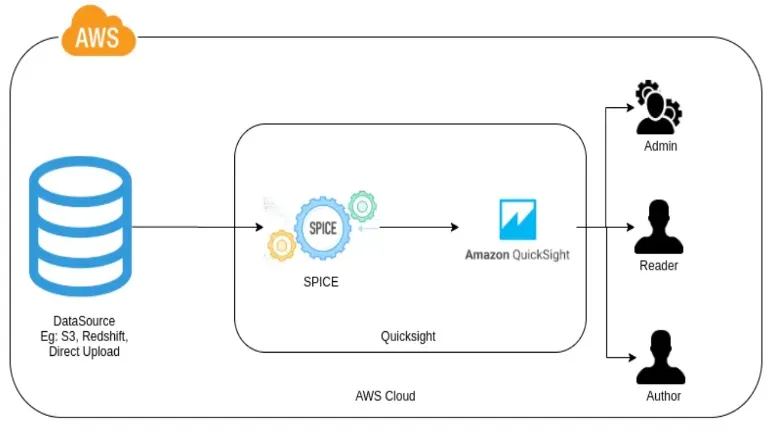
Exploring Data Sources, Datasets, Analysis, and Dashboards in AWS QuickSight
Datasource refers to the source of the data you want to analyze, such as databases, files, or AWS services. To pull in data for visualization, you connect QuickSight to these data sources.
A dataset is a prepared and transformed subset of data from the data source for analysis. It involves selecting specific tables, columns, or performing data cleaning and transformation tasks.
The analysis is the process where you create visual representations (charts, graphs, etc.) of your data. This is where you build your data visualizations and explore your data in detail.
A dashboard is a collection of analyses and visualizations that provide an at-a-glance overview of the metrics and key performance indicators (KPIs) important to your business. It is a comprehensive, interactive interface where users can monitor and analyze their data in a consolidated view.
Reasons for Deleting Data Sources in AWS QuickSight:
User Error:
One of the main causes of data source deletion in AWS QuickSight is user error. Users may accidentally remove critical data sources without realizing the impact of their actions. This can lead to the breakdown of all dashboards that depend on the data source.
Multiple Datasources with the Same Name:
The ability to create multiple datasources with the same name in AWS QuickSight can also lead to accidental deletion of data sources. This can cause confusion and increase the likelihood of deleting the wrong datasource if not managed carefully.
Preventive Measures:
- To implement preventative measures, understand the underlying reasons for unintentional data source deletion.
- Limit delete permissions for Quicksight users.
- Implement clear and unique naming conventions for data sources to prevent confusion and accidental deletions.
- Ensure users undergo thorough training on data management.
- Educate users on the possible repercussions of deleting data sources.
Challenges Encountered:
The deletion of data sources in AWS QuickSight can lead to loss of crucial information and disruptions in data visualization processes. Users may experience difficulties in reconstructing deleted data sources, affecting the overall efficiency and accuracy of their analytics. It is essential to address these challenges promptly to maintain the integrity of data visualization projects.
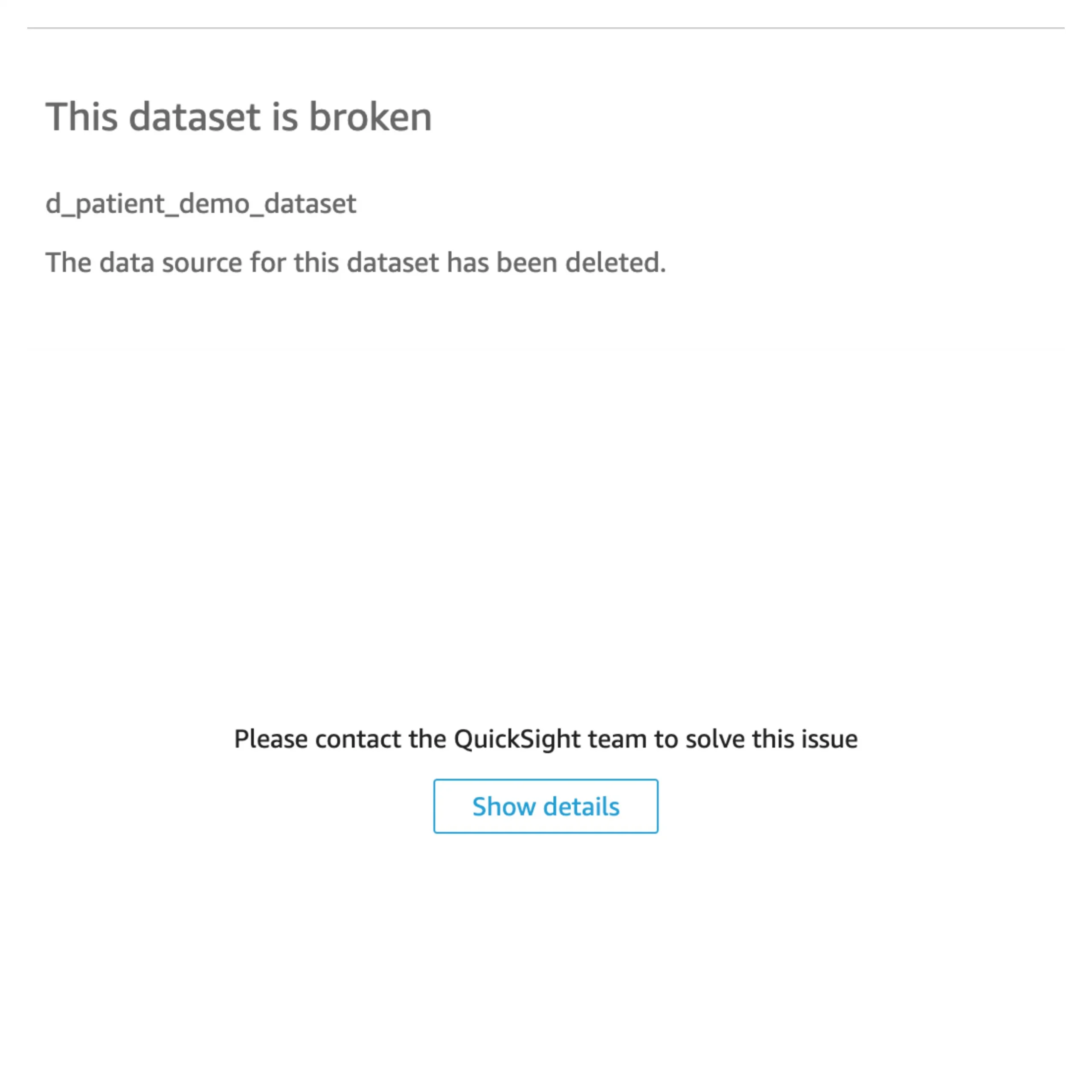
Prerequisites:
You must have the following prerequisites:
- An AWS account
- A Enterprise QuickSight account
- AWS Identity and Access Management (IAM)
- AWS Lambda
Solution Overview:
Detecting Deleted Data Sources
Identifying Associated Datasets
Restoring Deleted Data Sources
Updating Associated Datasets
IAM Policy for Recovering Deleted Datasources
When working with Amazon QuickSight, it’s essential to have the appropriate permissions to manage and recover datasets effectively. Below is an IAM policy that grants comprehensive permissions for creating, listing, getting, updating, describing, searching, and setting dashboards, analyses, datasets, and data sources in Amazon QuickSight.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "quicksight:CreateDataSource", "quicksight:ListDataSets", "quicksight:ListDataSources", "quicksight:ListAnalysis" , "quicksight:UpdateDashboard", "quicksight:UpdateAnalysis", "quicksight:UpdateDataSet", "quicksight:UpdateDataSource", "quicksight:DescribeDashboard", "quicksight:DescribeAnalysis", "quicksight:DescribeDataSet", "quicksight:DescribeDataSource" ], "Resource": [ "arn:aws:quicksight:::dashboard/*", "arn:aws:quicksight:::analysis/*", "arn:aws:quicksight:::dataset/*", "arn:aws:quicksight:::datasource/*" ] } ] }Detecting Deleted Data Sources :
There are two ways we can obtain those details.
- We can navigate to CloudWatch Logs and retrieve the relevant logs. From there, we can extract the deleted data source ID.
- If you don’t have CloudWatch Logs enabled, you can use the following code to get the list of data sources and their corresponding IDs.
The following Python script retrieves a list of all data sources and their respective IDs.
import boto3 aws_acct_region='your_region_name' def lambda_handler(event, context): sts = boto3.client('sts',region_name=aws_acct_region) aws_account_id = sts.get_caller_identity()['Account'] client = boto3.client('quicksight',region_name=aws_acct_region) # List data sources response = client.list_data_sources(AwsAccountId=aws_account_id) data_sources = response['DataSources'] # Prepare output data data_source_details = [['Name', 'DataSourceId']] for data_source in data_sources: data_source_name = data_source['Name'] data_source_id = data_source['DataSourceId'] data_source_details.append([data_source_name, data_source_id]) # Create CSV data csv_data = '\n'.join([','.join(map(str, row)) for row in data_source_details]) # Optional: Upload to S3 (replace bucket and key with your details) # bucket_name = 'your_bucket_name' # s3_key = 'file_name.csv' # s3_client = boto3.client('s3') # s3_client.put_object(Body=csv_data, Bucket=bucket_name, Key=s3_key) return { 'statusCode': 200, 'body': 'Data sources list retrieved successfully' }Explanation:
- Using the
stsclient, the script retrieves the AWS account ID. - It uses the
Boto3client to connect to the QuickSight service. - The
list_data_sourcesfunction retrieves a list of all data sources for the specified account. - The script iterates through each data source and extracts its name and ID.
- It generates lists of headers (
Name,DataSourceId) and data rows for each source. - The script converts the data into CSV format using list comprehension.
Identifying Associated Datasets:
Based on the data source ID we retrieved earlier, we can now identify all datasets created using that specific data source. This process involves querying the AWS QuickSight API to gather information about datasets associated with the given data source. We can identify the datasets linked to the specified data source by iterating through the list.
The following Python script retrieves a list of all data sources and their respective IDs.
import boto3 aws_acct_region='your_region_name' def lambda_handler(event, context): sts = boto3.client('sts',region_name=aws_acct_region) aws_account_id = str(sts.get_caller_identity()['Account']) data_source_id='your_data_source_id' data_source_arn = "arn:aws:quicksight:{}:{}:datasource/{}".format(aws_acct_region,aws_account_id, data_source_id) client = boto3.client('quicksight',region_name=aws_acct_region) # Get the list of datasets datasets = [] next_token = None while True: if next_token: response = client.list_data_sets(AwsAccountId=aws_account_id, NextToken=next_token) else: response = client.list_data_sets(AwsAccountId=aws_account_id) datasets.extend(response['DataSetSummaries']) next_token = response.get('NextToken') if not next_token: break # Extract dataset names and IDs data_source_details = [] for dataset in datasets: try: dataset_response = client.describe_data_set(AwsAccountId=aws_account_id, DataSetId=dataset['DataSetId']) except client.exceptions.InvalidParameterValueException as e: print(f"Error describing dataset {dataset['DataSetId']}: {e}") continue data_source_arn_ = None for physical_table_id, physical_table_details in dataset_response['DataSet']['PhysicalTableMap'].items(): if physical_table_details.get('CustomSql', {}).get('DataSourceArn'): data_source_arn_ = physical_table_details['CustomSql']['DataSourceArn'] break if data_source_arn_ == data_source_arn: data_source_details.append([dataset['Name'], dataset['DataSetId']]) # Write dataset names and IDs to a CSV string csv_data = '\n'.join([','.join(map(str, row)) for row in data_source_details]) # Upload the CSV data to S3 bucket_name = 'your_bucket_name' s3_key = 'file_name.csv' s3_client = boto3.client('s3',region_name=aws_acct_region) s3_client.put_object(Body=csv_data, Bucket=bucket_name, Key=s3_key) return { 'statusCode': 200, 'body': 'Dataset list uploaded to S3 successfully' }Explanation:
- Using the
stsclient, the script retrieves the AWS account ID. - It uses the
Boto3client to connect to the QuickSight service. - The
list_data_setsfunction retrieves a list of all data sets for the specified account. - List Datasets: The code uses the
list_data_setsAPI of the QuickSight client to retrieve a list of datasets in the AWS account. It paginates through the results if there are more datasets than the API can return in a single call. - Check Dataset Dependencies: To get detailed information about each dataset, the code uses the
describe_data_setAPI, including its physical table map. The code then verifies whether any physical tables within the dataset are associated with the data source of interest. Thedata_source_detailslist adds the name and ID of a dataset that depends on the data source.
Restoring Deleted Data Sources:
In this guide, we’ll delve into the essential steps required to recreate a data source in AWS QuickSight. This comprehensive process will help you restore connectivity and functionality to your datasets and analyses, ensuring minimal disruption to your operations.
Here’s a step-by-step approach to recreating a deleted data source:
- Gather Information: Before diving in, gather some key details about the deleted data source.
- Data Source ID:This unique identifier helps reference the specific data source.
- Data Source Type:Identify the type of data source (e.g., MySQL, PostgreSQL).
- Connection Details:This includes information like database name, username, and password (secure these!).
- Security Configuration:Note down any VPC connection details or SSL settings used by the original data source.
The Python script restores the deleted data source:
import boto3 aws_acct_region='your_region_name' def lambda_handler(event, context): sts = boto3.client('sts',region_name=aws_acct_region) client = boto3.client('quicksight',region_name=aws_acct_region) aws_account_id = sts.get_caller_identity()['Account'] # Specify the desired data source ID data_source_id = 'deleted_datasource_id' # Define the data source parameters data_source_parameters = { 'RdsParameters': { 'InstanceId': 'your_rds_instance_id', 'Database': 'your_database_name' } } data_source_name = 'data_source_name' data_source_type = 'MYSQL' vpc_connection_name ='your_vpc_connection_name' vpc_connection_arn = 'arn:aws:quicksight:{}:{}:vpcConnection/{}'.format(aws_acct_region,aws_account_id, vpc_connection_name) disable_ssl = False # Define the data source credentials data_source_credentials = { 'CredentialPair': { 'Username': 'give_your_username', 'Password': 'password' } } # Create the data source response = client.create_data_source( AwsAccountId=aws_account_id, DataSourceId=data_source_id, Name=data_source_name, Type=data_source_type, DataSourceParameters=data_source_parameters, Credentials=data_source_credentials, SslProperties={ 'DisableSsl': disable_ssl }, VpcConnectionProperties={ 'VpcConnectionArn': vpc_connection_arn } ) return response
Explanation:
The provided Python code snippet utilizing the Boto3 library demonstrates how to programmatically recreate a data source using the AWS SDK. This approach is helpful for automating the recreation process, especially if you’re dealing with multiple data sources.
Key Points in the Code:
- The
stsclient is used to retrieve your AWS account ID and ARN. - It defines the data source parameters specific to your database type (MySQL in this example).
- It specifies credentials and security configurations, such as VPC connections and SSL settings.
- The
create_data_sourcefunction creates a new data source with the provided details.
Updating Associated Datasets:
After recreating the data source, you must update all datasets that depended on the original source. Point them to the recreated data source to establish connectivity and ensure that your analysis and dashboards continue to function properly.
Backup the Dataset Configuration:
It’s critical to back up your datasets before making any updates. AWS QuickSight provides an option to export dataset settings, such as field mappings, data types, and customizations, into a JSON file. This file serves as a backup that allows you to recreate the dataset in its previous state if needed. Having this backup ensures that you can easily revert to a previous state if any issues occur during the deletion process.
The Python script backs up the dataset configuration.
import json import boto3 import csv aws_acct_region='your_region_name' client = boto3.client('quicksight',region_name=aws_acct_region) s3_client = boto3.client('s3',region_name=aws_acct_region) s3_bucket_name = 'your_bucket_name' def dump_dataset(account_id): datasets = [] dataset_id = [] response = client.list_data_sets(AwsAccountId=account_id) next_token: str = response.get("NextToken", None) datasets += response["DataSetSummaries"] while next_token is not None: response = client.list_data_sets(AwsAccountId=account_id, NextToken=next_token) next_token = response.get("NextToken", None) datasets += response["DataSetSummaries"] for i in datasets: dataset_id.append(i["DataSetId"]) # Create a list of dictionary keys (column names) column_names = ['id', 'name', 'physical_table', 'logical_table', 'mode'] # Write the dictionary data to a CSV file with open('/tmp/dataset.csv', 'w', newline='') as csv_file: writer = csv.DictWriter(csv_file, fieldnames=column_names) writer.writeheader() # Write column names as the header for i in dataset_id: try: res = client.describe_data_set( AwsAccountId=account_id, DataSetId=i ) dataset_dict = { 'id': res['DataSet']['DataSetId'], 'name': res['DataSet']['Name'], 'physical_table': res['DataSet']['PhysicalTableMap'], 'logical_table': res['DataSet']['LogicalTableMap'], 'mode': res['DataSet']['ImportMode'] } writer.writerow(dataset_dict) except Exception as e: print(e) continue file_name = 'your_file_name.csv' # Upload the CSV file to S3 s3_client.upload_file('/tmp/dataset.csv', s3_bucket_name, file_name) return dataset_dict def lambda_handler(event, context): sts = boto3.client('sts',region_name=aws_acct_region) aws_account_id = str(sts.get_caller_identity()['Account']) response = dump_dataset(aws_account_id) return { 'statusCode': 200, 'body': json.dumps('Successfully taken the backup of our datasets') }Explanation:
You can back up your dataset configurations from AWS QuickSight to an S3 bucket using the code snippet above, ensuring you have a copy of your datasets in case you need to restore them in the future.
Modify the dataset configuration:
Retrieve Dataset Information:
Use the describe_data_set API to retrieve detailed information about each dataset, including its ID, name, and current configuration.
Modify Dataset Configuration:
To update the configuration as needed, edit the retrieved dataset information. This may include changing field mappings, data types, or any other dataset settings.
To remove unnecessary information, edit the response:
- Remove lines 2, 3, 4, 7, 8 starting with “Status,” “Dataset,” “Arn,” “CreatedTime,” and “LastUpdatedTime.”.
- Remove lines containing “ConsumedSpiceCapacityInBytes” and “RequestId”.
- Remove the JSON block for “OutputColumns”.
Update Dataset Configuration:
To apply the modified configuration to the dataset, use the update_data_set API.
Here is a Python script that shows you how to modify the dataset configuration:
import boto3 aws_acct_region='your_region_name' def update_dataset(dataset_id): # Define the account ID account_id = "your_account_id" client = boto3.client("quicksight",region_name=aws_acct_region) try: response = client.describe_data_set( AwsAccountId=account_id, DataSetId=dataset_id ) # Edit the dataset description dataset_description = response["DataSet"] # Remove unnecessary keys from the dataset description dataset_description.pop("Arn", None) dataset_description.pop("CreatedTime", None) dataset_description.pop("LastUpdatedTime", None) dataset_description.pop("ConsumedSpiceCapacityInBytes", None) dataset_description.pop("RequestId", None) dataset_description.pop("OutputColumns", None) dataset_description.pop("RowLevelPermissionDataSet", None) # Update the dataset with the modified description update_params = { "AwsAccountId": account_id, "DataSetId": dataset_id, **dataset_description # Include all remaining keys from the dataset description } response = client.update_data_set(**update_params) print(f"Dataset {dataset_id} updated successfully!") except Exception as e: print(f"Error updating dataset {dataset_id}: {str(e)}") def lambda_handler(event, context): # Define the list of dataset IDs dataset_ids = ['your dataset ids' ] for dataset_id in dataset_ids: update_dataset(dataset_id)
Conclusion:
Ensuring data integrity and resilience in AWS QuickSight requires a proactive approach that combines preventive measures, systematic identification of deleted data sources, and automated processes for recreating and updating datasets. By implementing stringent permissions, clear naming conventions, and comprehensive user training, organizations can reduce the risk of accidental data source deletions. Regularly backing up dataset configurations to S3 and using scripts to update configurations post-recreation ensures data continuity, enhancing data governance, and minimizing disruptions in data visualization and analytics workflows within AWS QuickSight.
References:
