
In the world of data management, efficient handling and organization of data becomes crucial as datasets grow exponentially. One effective approach to manage large datasets is through data partitioning. This blog will delve into why data partitioning matters, different strategies for partitioning data, and considerations for implementing partitioning in Azure Data Lake and Azure Synapse.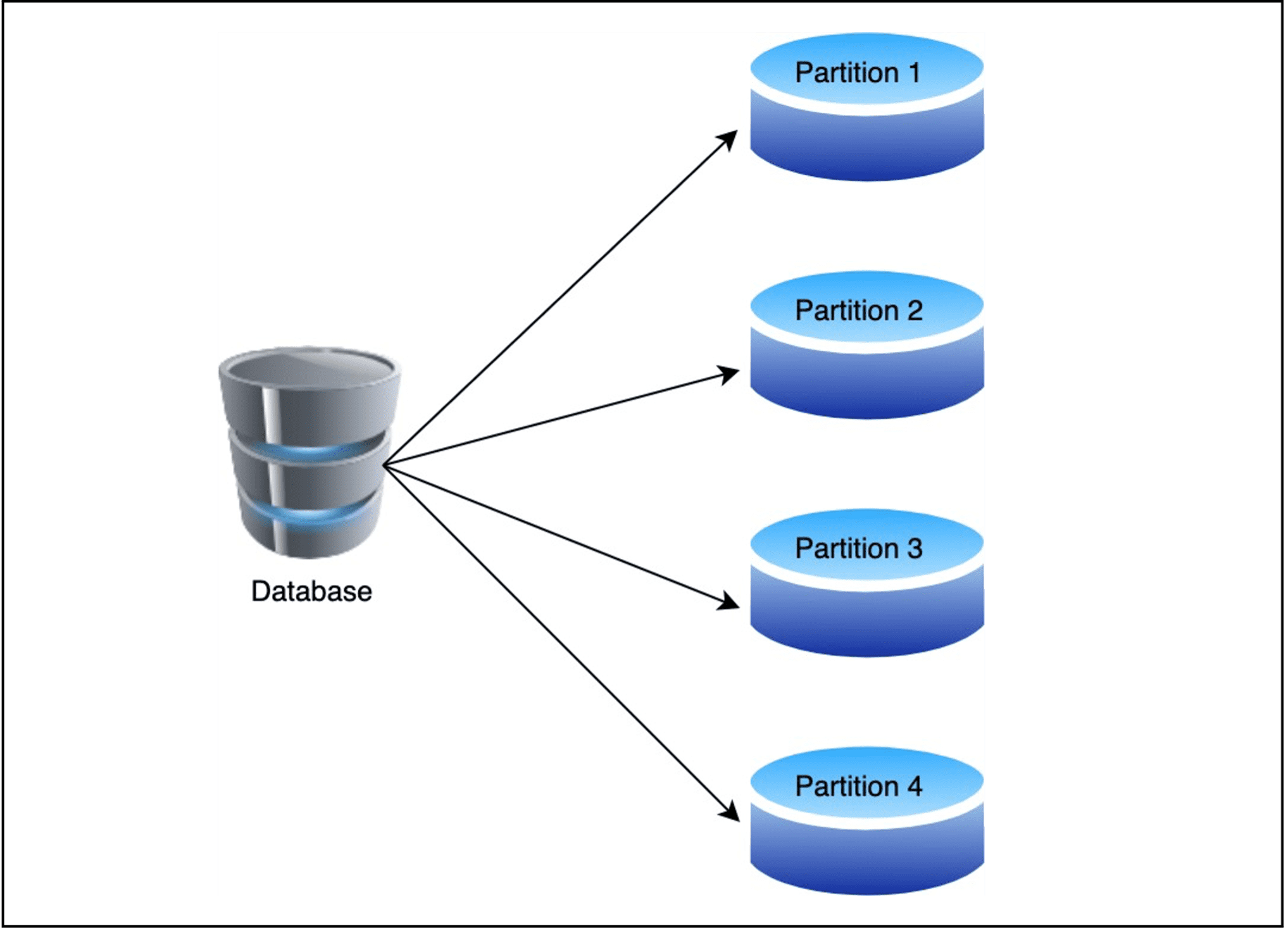
Figure 1 – Data Partitioning
1. Improve Scalability
As data grows, partitioning allows splitting data into manageable chunks, enhancing scalability while maintaining quick data access.
2. Improve Performance
Reading specific content from a partition is faster than scanning the entire dataset. It’s akin to retrieving a single file from a cabinet rather than searching through the entire cabinet.
3. Improve Security
Different security measures can be applied to various partitions, providing enhanced protection for sensitive data.
4. Improve Availability
Spreading data across partitions prevents a single point of failure, ensuring better availability of data.
5. Improve Cost Savings
Opportunity to store lower priority data on more cost-effective storage options.
What are the different Partitioning Strategies?
- Vertical Partitioning
- A single partition in a table contains subsets of fields organized based on usage Frequently accessed columns are grouped together in one partition, while less frequently used columns are placed in another. The partitions can be linked through common attributes for efficient querying and data retrieval.
- Separates Static and Dynamic data e., slow moving data can be cached in memory by the application, improving its performance.
- Placing sensitive data in a separate partition with higher level of
In this example, the application regularly queries the Employee FirstName & EmployeeLastName, description when displaying the Employee details.
EmployeePicture is held in a separate partition because it is less frequently needed.
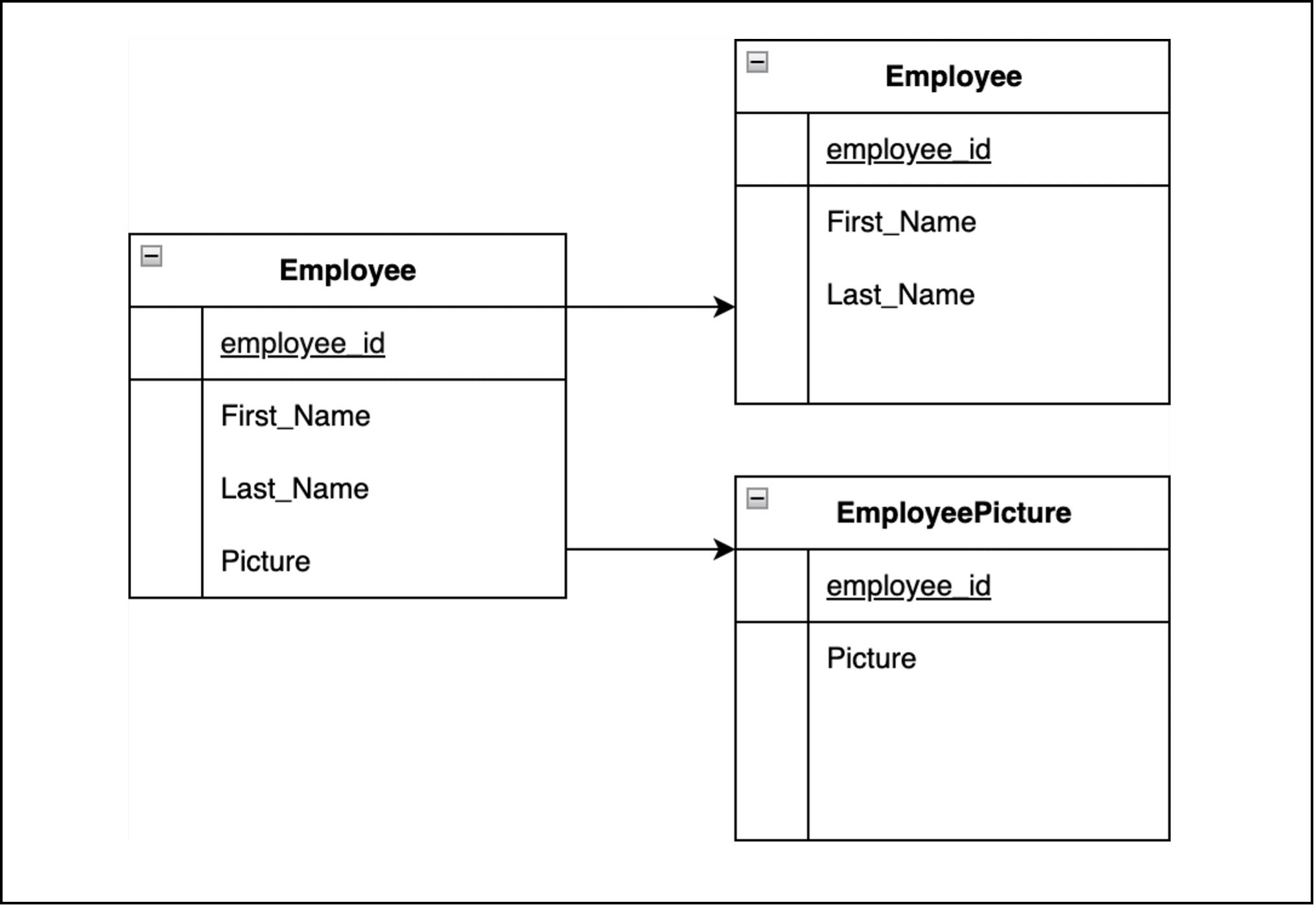 Figure 2 – Vertically partitioning data by its pattern of use.
Figure 2 – Vertically partitioning data by its pattern of use.
- Functional Partitioning
- Aggregate data by purpose within a bounded context. Imagine a scenario where HR activities are segregated in one designated area, distinct from another section dedicated to IT This ensures that HR data is isolated in one partition, while IT data resides in a separate partition, each focused on their respective tasks.
- Partitions for Separate workload types e., Read only data can be placed in separate partitions for faster read performance.
Below Figure shows an overview of functional partitioning where inventory data is separated from Invoices data.
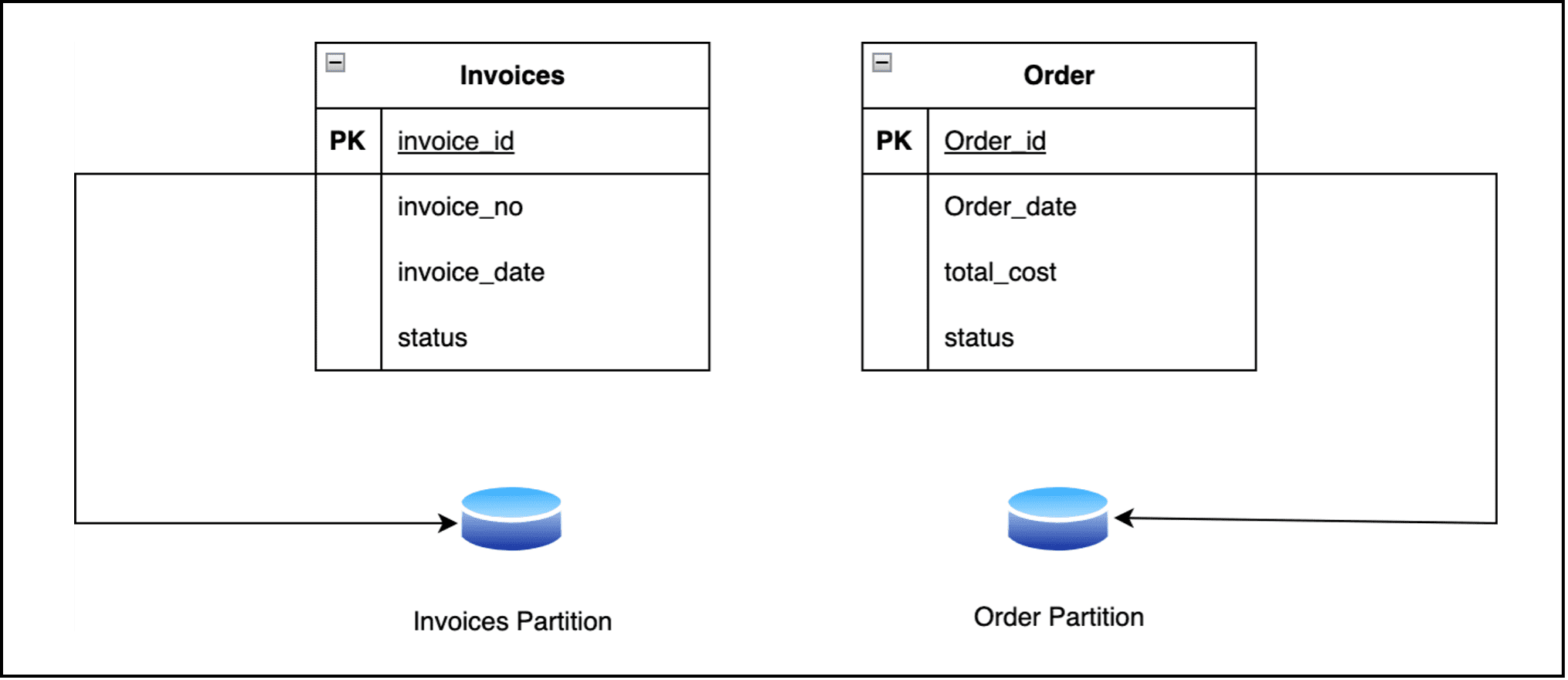 Figure 3 – Functionally partitioning data by bounded context or subdomain.
Figure 3 – Functionally partitioning data by bounded context or subdomain.
Note: The choice between vertical and functional partitioning depends on the type of data, its usage, and the required workload type.
Partitioning in Azure Data Lake
How Partitioning Works?
- The Partition Key for Blob & Data Lake storage consists of (Account+container+blob). Ex: (https:// presidio.azuredatalaknet / landing / file_name.parquet). This gives the partition key when working with Azure data lake.
- Range Based Partitioning: Data is split into ranges and load balanced across the storage system. Once the load increases to certain point, it is split to smaller
In the below example Partition 1 contains January & February data, once the partition load hits threshold limit, it can split into January & February as separate partitions.
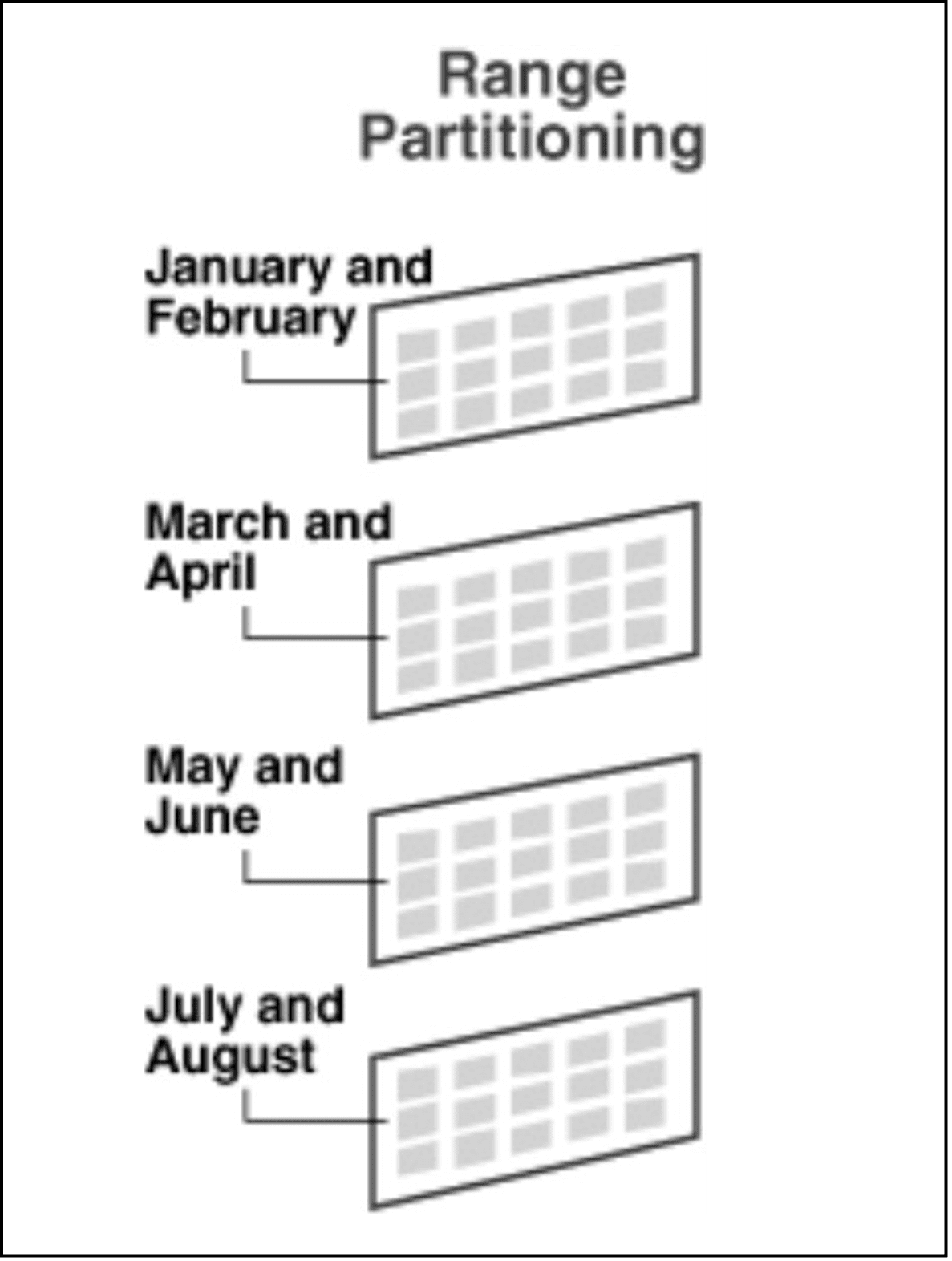 Figure 4 – Range Based Partitioning
Figure 4 – Range Based Partitioning
Note: The naming convention for the account, container, and blob impacts the partition key. In the background, the partition key is utilized for executing range-based partitioning.
Performance Considerations
- Name with Care: Use a proper naming convention (Account, Container, Blob) to avoid data dumping in one bucket. Consider using hashing function to prefix
- Parallel Operation: Enable more parallel reads and writes for improved
- Pruning: Eliminates unneeded partitions during data
- Keep Partition Size Smaller: Enhance query response time by maintaining smaller partition
Note: Regular pruning of data and smaller partition sizes contribute to better performance and reduced administrative overhead.
Scalability Considerations for Azure Data Lake
- Plan Ahead: Estimate size and workload of each partition to
balance. Analyzing the application needs every now and then will help project the scalability requirements.
- Know the Limits: Be aware of Azure Infrastructure limits on a single partition store and create more partitions if
- Monitor: Ensure the distribution is working as Because reality doesn’t always match with our predictions.
Availability Considerations for Azure Data Lake
- Prioritize: Apply availability and backup plans based on data criticality in each
- Be Mindful of Time: Identify the best times to take partitions offline for
Partitioning in Azure Synapse
How Partitioning Works?
- Massively Parallel Processing (MPP): Clients connect to the control/ master node, which distributes queries to multiple compute nodes for parallel
- Default Distribution: Data is automatically distributed across 60 default partitions. Ex: No of partition you want to make (10) * 60 Default Partitions = 600 Consider this factor while creating the partition else the data partition would become so thin.
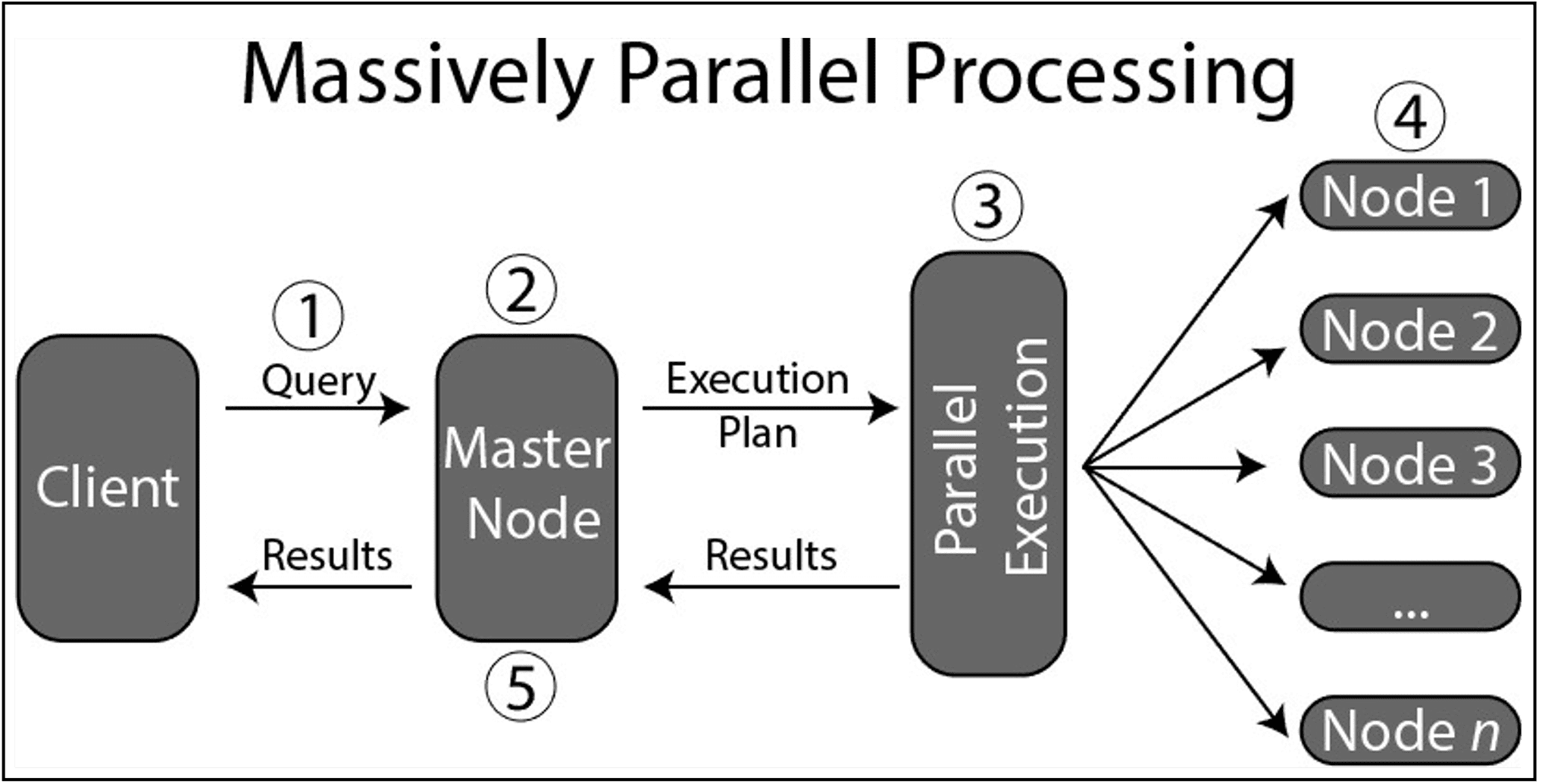 Figure 5 – Massively Parallel Processing
Figure 5 – Massively Parallel Processing
Performance considerations
- Scope queries to as few partitions as possible to minimize data Biggest villain in these systems are data shuffling and excessive data shuffling during queries poses a significant challenge.
- Avoid Cross Partition Joins, constantly joining different partitions can slow down
- Utilize Partition Operations: Implement partition switching, merging, and deletion for faster operations on larger These are well crafted partition operations for better performance. Avoid using Insert/update/delete which has heavy transactional cost.
- Do Not Over Partition: Aim for a reasonable number of partitions to avoid performance Ideally it would be 10s or 100s of partition but not in 1000s.
In summary, effective data partitioning is a key strategy for managing and optimizing large datasets. Whether in Azure Data Lake or Azure Synapse, understanding the nuances of partitioning strategies and implementing best practices can significantly enhance system performance, scalability, and availability.
Use Case:
An e-commerce platform operating on Azure that experiences a high volume of customer orders daily. The goal is to optimize real-time order processing and analytics by implementing Azure Data Partitioning.
Solution Overview:
The platform utilizes Azure SQL Database for storing customer order data. Azure Data Partitioning is employed to divide the order table into partitions based on the order creation timestamp, with each partition representing a specific day. This allows the system to efficiently manage and query the data in real-time.
Implementation Steps:
- Partitioning Strategy:
- Orders table is partitioned by the order creation
- Each partition represents a single day’s worth of orders.
- Applying Partition Scheme:
Associate the partition function with the orders table.
- Populating Data:
Load historical and ongoing order data into the partitioned table. Real-time Order Processing
- Real-time Order Processing
As new orders are placed, they are automatically assigned to the correct partition based on the order creation timestamp.
Performance Metrics
Query Response Time Improvement
- Without Partitioning: Scanning the entire unpartitioned order table for a specific day might take several
- With Partitioning: Querying the partition corresponding to the target day reduces response time
Reduced I/O Operations
- Without Partitioning: Full table scans lead to higher I/O operations, affecting overall database
- With Partitioning: Accessing only the relevant partition minimizes I/O operations, resulting in improved
Concurrency and Scalability
- Without Partitioning: Concurrent queries on the entire order table may lead to contention and reduced
- With Partitioning: Queries targeting different partitions can be executed concurrently, enhancing system
Storage Efficiency:
- Without Partitioning: Unoptimized storage utilization as all data is stored in a single
- With Partitioning: Storage is more efficiently used as data is distributed across partitions based on order creation
Deep Dive to Performance Metrics
Comparing the real-time query performance between querying 1 GB of unpartitioned data and querying the same amount of data but with partitioning applied, the data is partitioned by date, as mentioned in the above use case.
Unpartitioned Data
Data Volume: 1 GB of order data stored in a single table without partitioning.
Partitioned Data
Data Volume: 1 GB of order data distributed across multiple partitions, each representing a specific day.
Metric Parameters:
| Metric | Unpartitioned | Partitioned |
| Query Response Time: | The query may need to scan the entire 1 GB table, resulting in a longer response time. | Querying a specific partition based on the date range can significantly reduce response time. |
| I/O Operations: | Full table scans can lead to higher I/O operations, affecting overall database performance. | Accessing only the relevant partition minimizes I/O operations, potentially improving throughput. |
| Concurrency: | Concurrent queries on the entire table may lead to contention and reduced concurrency. | Queries targeting different partitions can be executed concurrently, enhancing system scalability and concurrency. |
| Scalability: | Scalability may be limited due to contention during concurrent queries. | Better scalability as queries can be parallelized across partitions. |
Results:
| Metric | Unpartitioned | Partitioned |
| Query Response Time: | Longer query response time, especially as data volume increases. | Significantly reduced query response time, making real-time queries more efficient. |
| I/O Operations: | Higher I/O operations due to full table scans. | Reduced I/O operations as only relevant partitions are accessed. |
| Concurrency: | Potential contention and reduced concurrency during concurrent queries. | Improved concurrency as queries can be parallelized across partitions. |
| Scalability: | Limited scalability due to contention. | Better scalability with the ability to scale horizontally by adding more partitions. |
Conclusion
Implementing Azure Data Partitioning in this e-commerce scenario optimizes real-time order processing, providing tangible improvements in query performance, reduced I/O operations, enhanced concurrency, scalability, and efficient storage utilization. Performance metrics will vary based on factors such as data volume, query complexity, and system configuration.
In a real-time query scenario, partitioned data provides clear advantages over unpartitioned data, including faster query response times, reduced I/O operations, improved concurrency, and better scalability. The specific performance gains will depend on factors such as the complexity of the query, indexing, and the underlying hardware and network infrastructure.
**Above use case is constructed with help of Online AI Tools.
Image Source:
https://subscription.packtpub.com/book/data/9781789533880/6/ ch06lvl1sec51/massively-parallel-processing https://www.researchgate.net/figure/Horizontal-partitioning-techniques-List- Range-and-Hash-22_fig2_297764812
