
Part 1 – Introduction to the world of MLOps
Welcome to the first part of a multi-series Blog on MLOps. Through this series, we shall learn the industry stands of deploying a Machine-learning pipeline using the proven MLOps methodology and how global enterprises are successfully doing it at scale by using the right mix of people, processes, and technology.
Below is the breakup of objectives and the upcoming blogs on MLOps
- Part 1 – Introduction to the world of MLOps – What and Why of MLOps?
- Part 2 – Deep Dive into individual components of MLOps (Including tools/Services from AWS)
- Part 3 – Sample architectures and low-level implementation examples
Introduction
MLOps – Machine Learning Operations
The emergence of Cloud Computing (availability of powerful scalable machines) has an appetite to leverage enterprise data to uncover groundbreaking business insights. This has led to a huge potential for advanced analytical approaches like Machine Learning, Deep Learning and Artificial intelligence.
With the increasing number of ML-related projects and the attached complexities, there is a pressing necessity to reduce the overall timelines involved in developing, experimenting, deploying, and monitoring these ML pipelines.
Organizations have also started exploring tools and frameworks that reduce the amount of human involvement in monitoring and maintaining these advanced decision-making entities.
And that is where the MLOps has taken the center stage in helping enterprises address the above-mentioned aspects of ML delivery.
A Glossary upfront
Machine Learning – Machine Learning is the field of study that gives computers the capability to learn without being explicitly programmed
Data Pipeline – A set of tools and processes used to automate the movement and transformation of data between a source and a target
Operations – A Managed process to support the life cycle of a Software/Application in a live environment
Feature – An individual measurable property or characteristic of a phenomenon. A data entity which decides model training, tuning and outcome
Model – A trained and packaged entity tasked to solve a specific business problem
A Typical ML pipeline
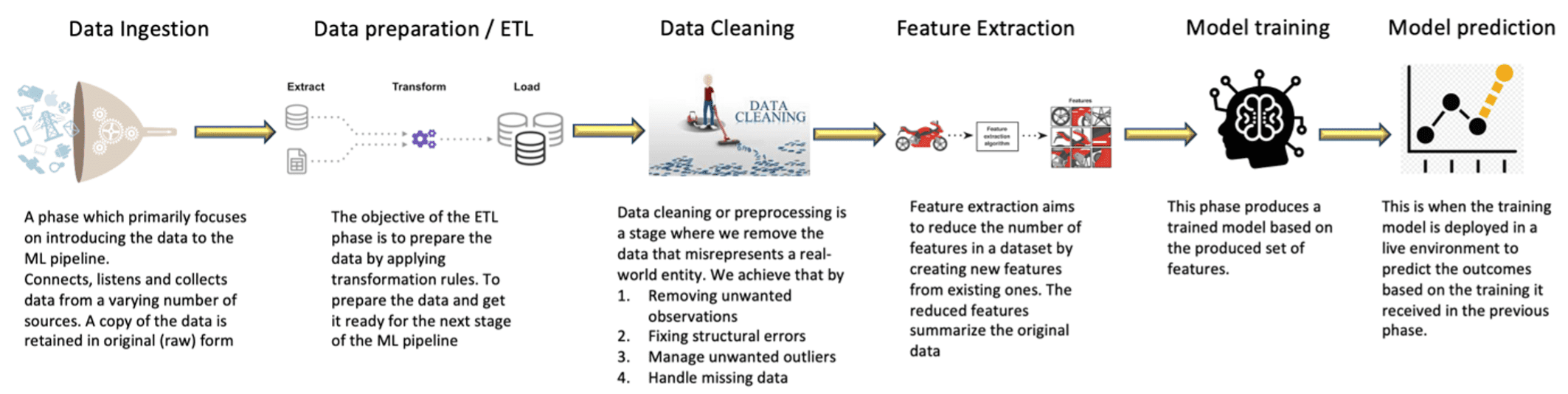 Objectives of MLOps
Objectives of MLOps
Below are some of the objectives of MLOps,
Faster time deployment – One of the primary objectives of MLOps is quicker time to market. From ideation, data identification, to model creation and deployment, the methodology tries to automate every step involved in a successful ML implementation
Fail fast and learn quick – As with any agile development methodology, ML development also involves iterations to learn more about the data and its relevance to the business problem. It is very crucial to efficiently iterate, learn from every iteration, and fine-tune the model
Reduce manual intervention – This is a key aspect to consider not only to reduce the efforts and eliminate errors by automating every possible part of a ML Pipeline. Preparing a dataset, monitoring the model performance, retraining the model and many more parts of an ML process demands utmost accuracy
Monitoring and alerting – Monitoring and managing a ML product in production is slightly different from managing a typical software product. In the case of ML, the machine has a brain and requires a special process to monitor that it is making the right decisions without human involvement. MLOps enables ML pipelines to be more proactive in reporting failures, invoking retraining automatically when the accuracy goes below a certain threshold
Compliance management – When it comes to decision making, deploying an unbiased model, and ensuring that voluntary or involuntary bias is not introduced in the ML decision-making is a key aspect of being compliant. Some of the example decisions which an ML model is intended to take include credit risk assessment, demographic analysis, and other sensitive socio-cultural outcomes. In such crucial environments, it is important to ensure that the model is performing without any bias towards certain classes of people/demography.
Reproducibility (idempotent) – Idempotency is a property which ensures that a given ML pipeline produces the same set of results for a given set of inputs for any number of iterative runs
MLOps ensures semantic versioning of all involved components like input datasets, processed datasets, Metadata, Models, and outputs. The artefacts are stored in separate logical stores to identify every unique training/prediction iteration.
Measurability – MLOps uses the right mix of tools and frameworks to capture a range of metadata related to model accuracy, performance, and operational metrics. It implements automated monitoring, alerting and decision-making on these data points to constantly probe into the model performance and ensure its relevance in serving the business problem.
MLOps-enabled landscape
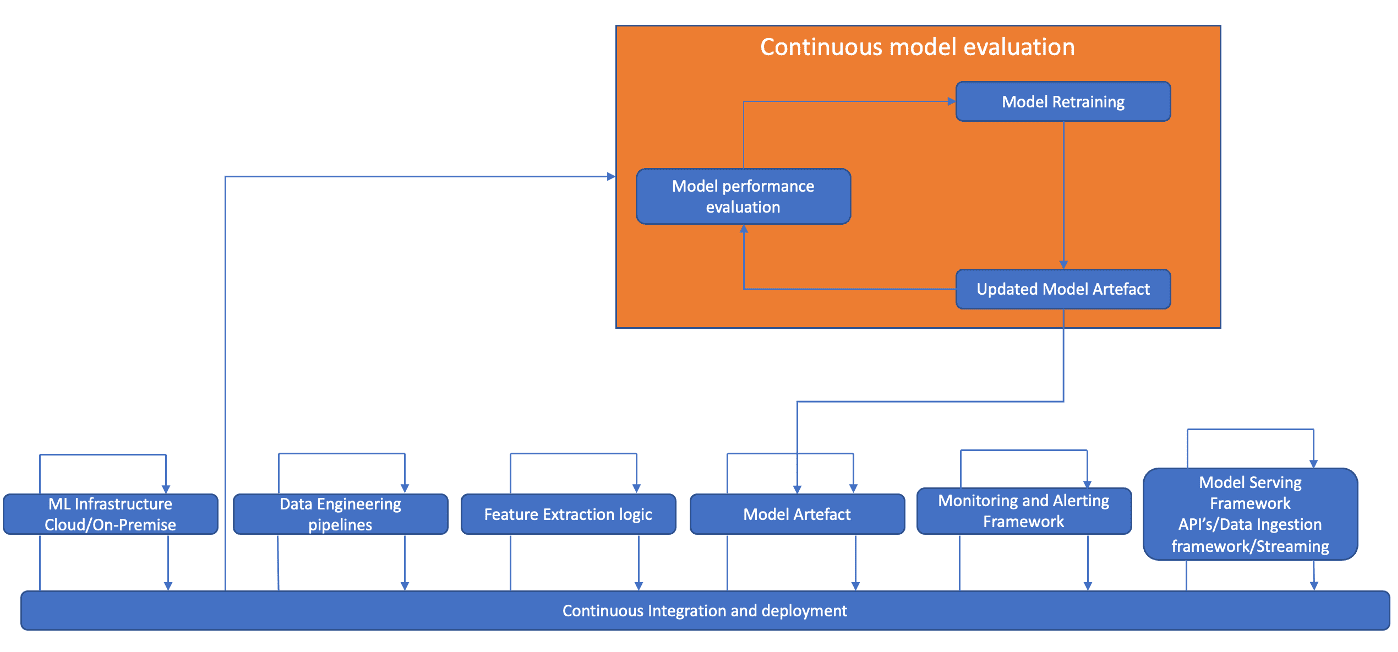
From the above landscape we could derive that below are the high level logical areas of an ML Ops implementation landscape.
The key backbone of a matured MLOps landscape is automation and continuous integrations. Seamless integrations are indispensable in MLOps. The input data to the model, the model retraining, the model deployment, model monitoring and integrating the results from the model back to the destination should all be automated and integrated into a single ecosystem.
Automation around this space is not new and is absolutely essential from an effort saving perspective, but also to eliminate human errors and biases. To keep the model producing and predicting relevant ecosystem, the entire pipeline has to be automated for deployment and promotion across various different environments.
Components of MLOps
- Infrastructure automation
- Data Engineering
- CI/CD and environment management
- Model packaging and deployment
- Model testing and continuous evaluation
- Model serving
- Monitoring and Alerting
A deep dive into each of the above areas along with the AWS services/reference architectures would be the focus for the part 2 of this blog.
MLOps on AWS
In the upcoming blog we would be discussing more about how to implement these theoretical concepts of MLOps on AWS. Below will be the high-level services and modules that would be covered:
- SageMaker MLOps
- MLOps Workload orchestrator framework
- Codepipeline/codebuild/codecommit integrations for MLOps
- MLOps Orchestration – Dagster/Airflow/Kubeflow on AWS
- MLflow on AWS
Stay tuned and Happy exploring!!
