
Our experts are thinkers AND doers focused on accelerating business outcomes. To showcase our deep expertise, we created a blog series called “The Digital Build.”

In today’s world, software advancements often come with high risks, regardless of improvements in security, high availability, visibility, and robust infrastructure. Every modern technology that aims to ease the ever-increasing demands of IT operation teams also brings new challenges with it.
For example, suppose our application is deployed to the EKS Kubernetes cluster and someone accidentally removes the deployments or services causing the application to go down. In that case, there is no visibility into how to make the applications available quickly.
We found GitOps practices are remarkably effective in deploying resilient Kubernetes infrastructure. ArgoCD is one of the GitOps tools. It provides continuous synchronization between Git and Kubernetes infrastructure.
What are GitOps and ArgoCD?
GitOps is a way of implementing Continuous Deployment for Kubernetes applications. The core idea of GitOps is having declarative descriptions of the desired state of infrastructure in a Git repository. This is like a source code and an automated process that matches these desired and current states of infrastructure. It allows developers to only push commits to the repository whenever they deploy to the infrastructure while an automated system handles the rest.
This is where ArgoCD comes into play. It completes the most crucial step of GitOps by ensuring that the repository and production environment states are coordinated. It reports & visualizes any deviation as well as provides mechanisms to synchronize the live state automatically or manually to the desired target state.
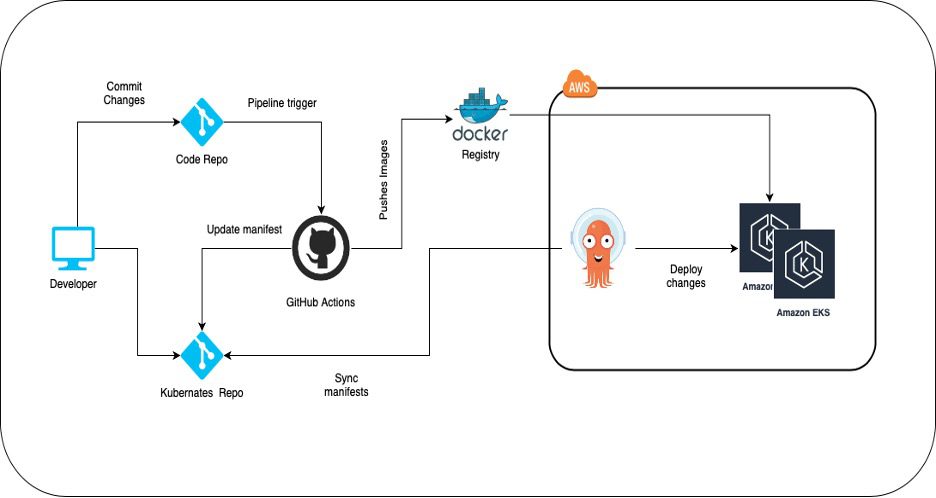 GitOps Workflow
GitOps Workflow
Why ArgoCD?
The main drawback of our CI/CD pipeline was application configuration management across environments and clusters. Whenever there was a change or a new feature for our applications, we had to apply these changes manually or keep jobs with specific kubeconfigs for each cluster to do automatic deployments. We wanted to automate all these processes and become closer to Continuous Deployment.
Features of ArgoCD;
- We can make deployments to different environments and clusters from a single source of truth.
- Deployment changes are reflected in all clusters dynamically and instantly.
- It provides a two-sided syncing feature. ArgoCD recognizes the changes on our configurations and starts synchronizing Kubernetes and if any deviation is identified on the Kubernetes side, it is synchronized back to its desired state. Without ArgoCD, Kubernetes resources would be unsynced until the next deployment.
- Just one-line changes in the target cluster work to relocate an application from one cluster to another cluster
- To increase the number of replicas, we had to wait for GitHub jobs in the pipeline to schedule and run. Now, it is just a change in the Git repository, and we can scale up instantly.
- It provides CLI and a user-friendly web UI for Kubernetes resources.
For more information, refer to the official documentation.
 Multicluster Deployment by ArgoCD
Multicluster Deployment by ArgoCD
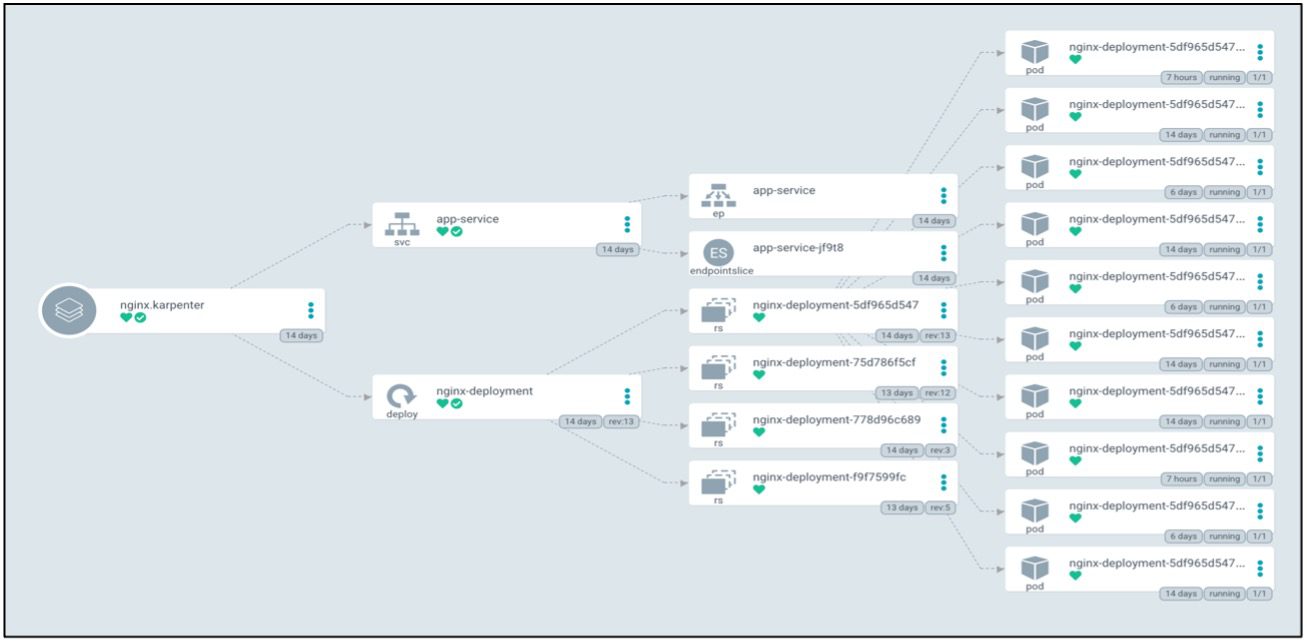 Fine Grain visibility of EKS Workload
Fine Grain visibility of EKS Workload
How Does Chaos testing make EKS clusters more fault-tolerant and highly available?
How can we test if our system can survive faults in reality?
Assuming an application is running on EKS cluster,
- What happens if one of the nodes fails?
- What happens when AZ outage occurs?
- Are all applications being retried?
- What happens if the network is slow?
So many things can go wrong. It is not possible to understand the consequences upfront. Therefore, an innovative approach emerged called Chaos Engineering.
With Chaos Engineering, we simulate faults in our systems and observe the consequences. We can simulate faults as often as we wish. We do not have to wait for one day a year when things go wrong. AWS released Fault Injection Simulator (FIS) as a tool to run controlled fault experiments within our AWS accounts.
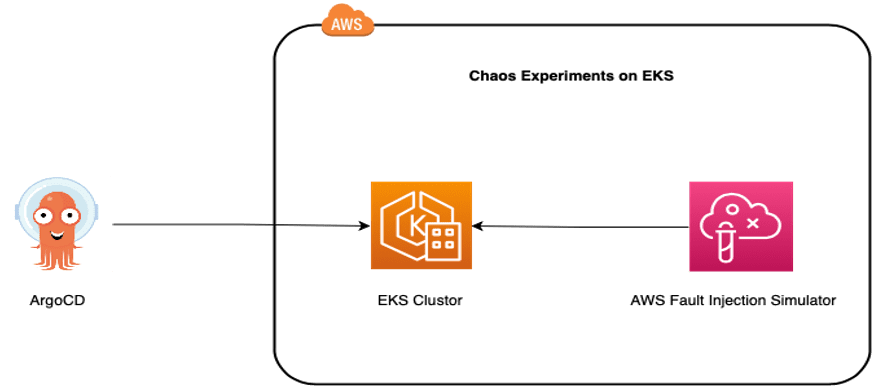 Chaos Experiments on EKS Cluster
Chaos Experiments on EKS Cluster
When we inject chaos tests into the EKS node group it will take the nodes down and impact on the application modules. To prevent these attacks, we will enable the cluster autoscaler, which helps to scale up and down the nodes dynamically.
This interrupts any remaining pods on the node. However, you can prevent this by ensuring that the pods that are expensive to evict are protected by a tag recognized by the Cluster Autoscaler. Achieving the right size of a Kubernetes cluster node is not an easy task. If the number of provisioned nodes is too high, the resources may be underutilized and if it is too low, no new workloads can be scheduled on the cluster.
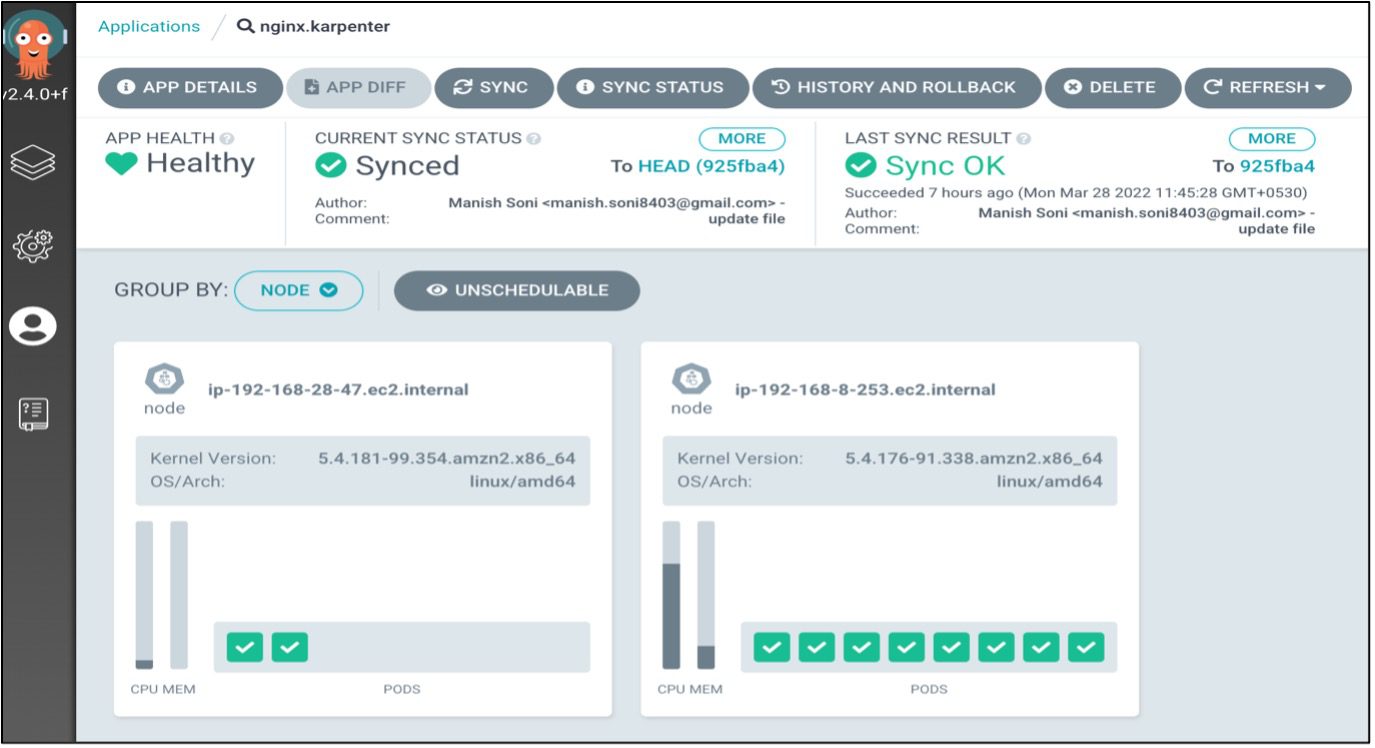
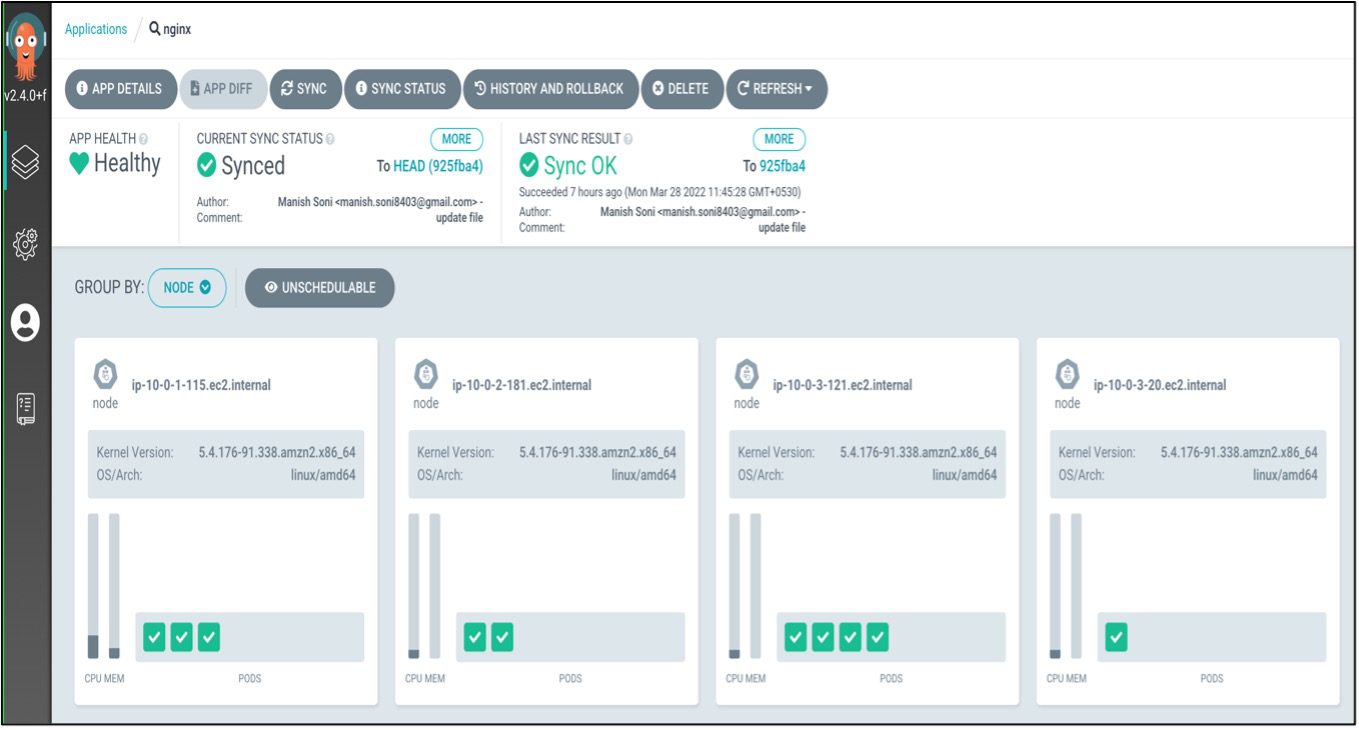 EKS Nodes Before Applying Chaos Experiments
EKS Nodes Before Applying Chaos Experiments
 EKS Nodes After Applying Chaos Experiments
EKS Nodes After Applying Chaos Experiments
AWS launched a new generation autoscaler called Karpenter. Karpenter is an open-source, flexible, high-performance Kubernetes cluster autoscaler built by AWS, that was released at re:Invent 2021.
Why Karpenter?
Karpenter can make API calls directly to EC2 instances. Instead of leveraging autoscaling groups that require a predefined set of instance types, Karpenter can make optimal EC2 instance choices to satisfy all the constants.
Karpenter automatically provisions new nodes in response to unschedulable pods. Karpenter observes events within the Kubernetes cluster and then sends commands to the underlying cloud provider. We can see the following working strategy of Karpenter:
- Watching pods that the Kubernetes scheduler has marked as unschedulable.
- Evaluating scheduling constraints (resource requests, nodeselectors, affinities, tolerations, and topology spread constraints) requested by the pods.
- Provisioning nodes that meet the requirements of the pods.
- Scheduling pods to run on new nodes and removing the nodes when they are no longer needed.
- Karpenter handles Pod Disruption Budgets (PDBs) by using a backoff retry eviction strategy. Pods will never be forcibly deleted, so pods that fail to shut down will prevent a node from deprovisioning.
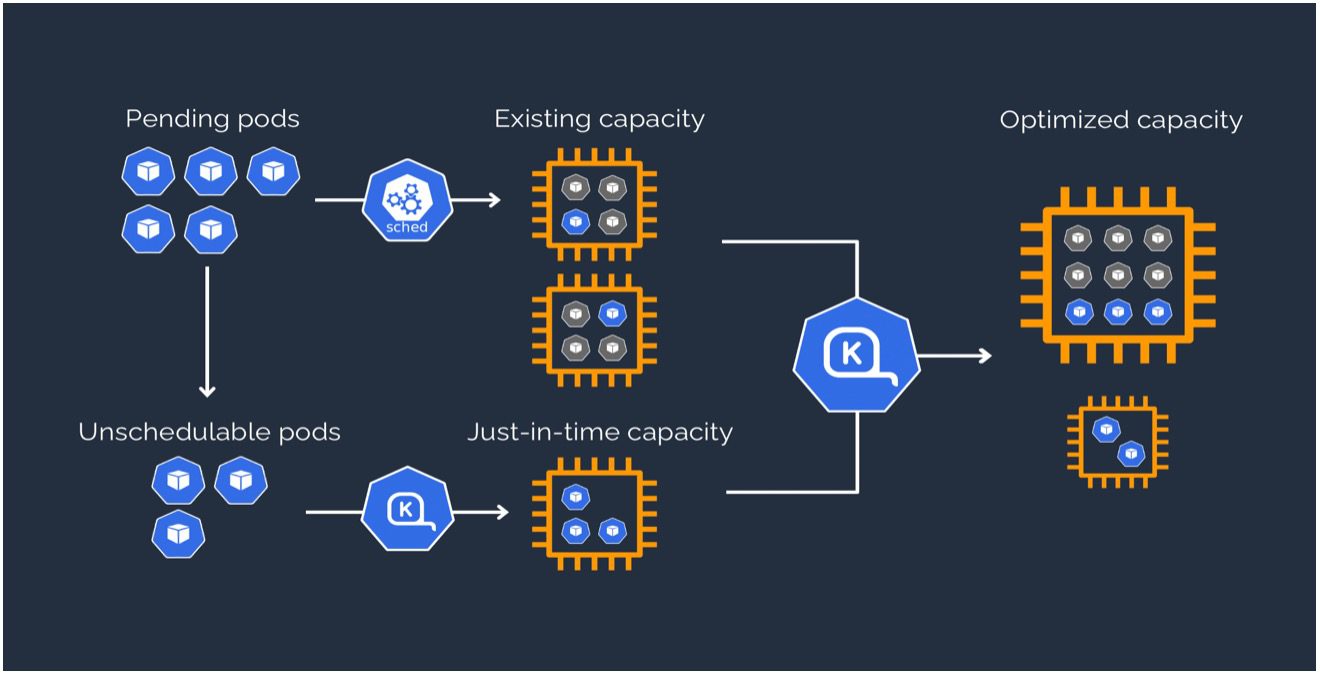 Karpenter Workflow
Karpenter Workflow
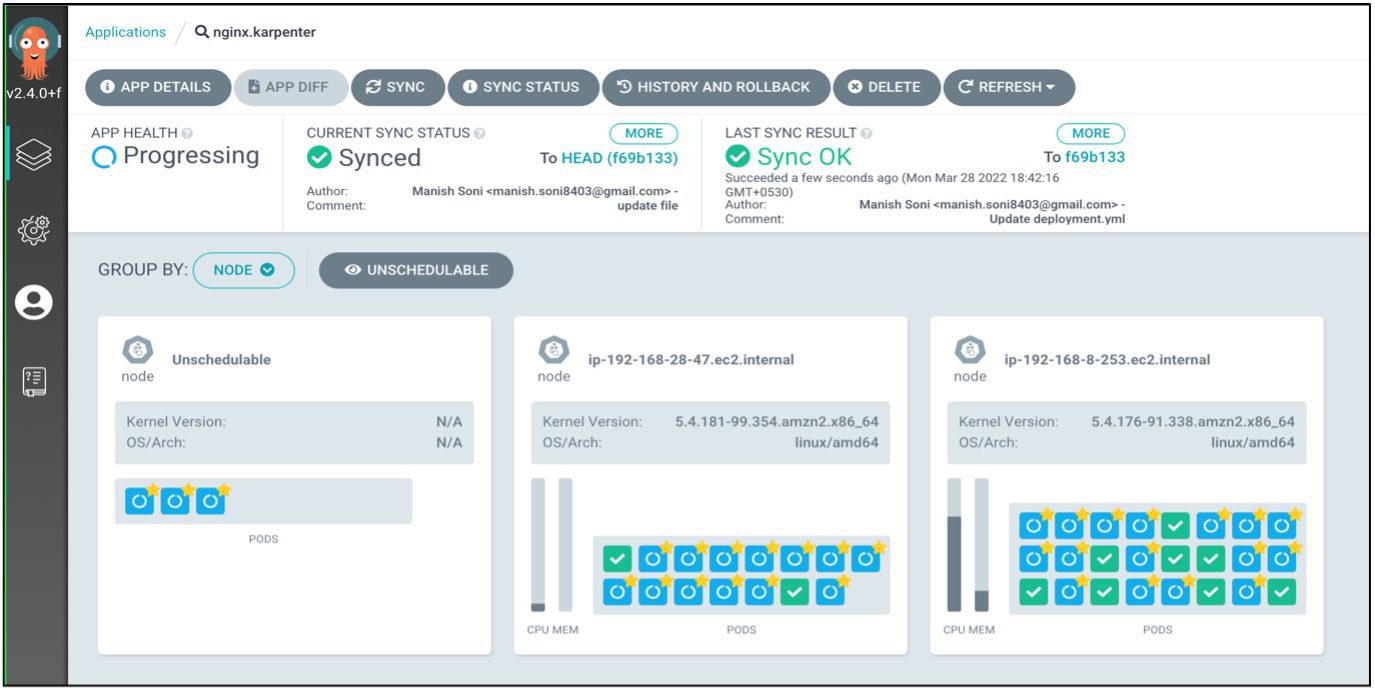 Scheduled and Unscheduled workload Managed by Karpenter
Scheduled and Unscheduled workload Managed by Karpenter
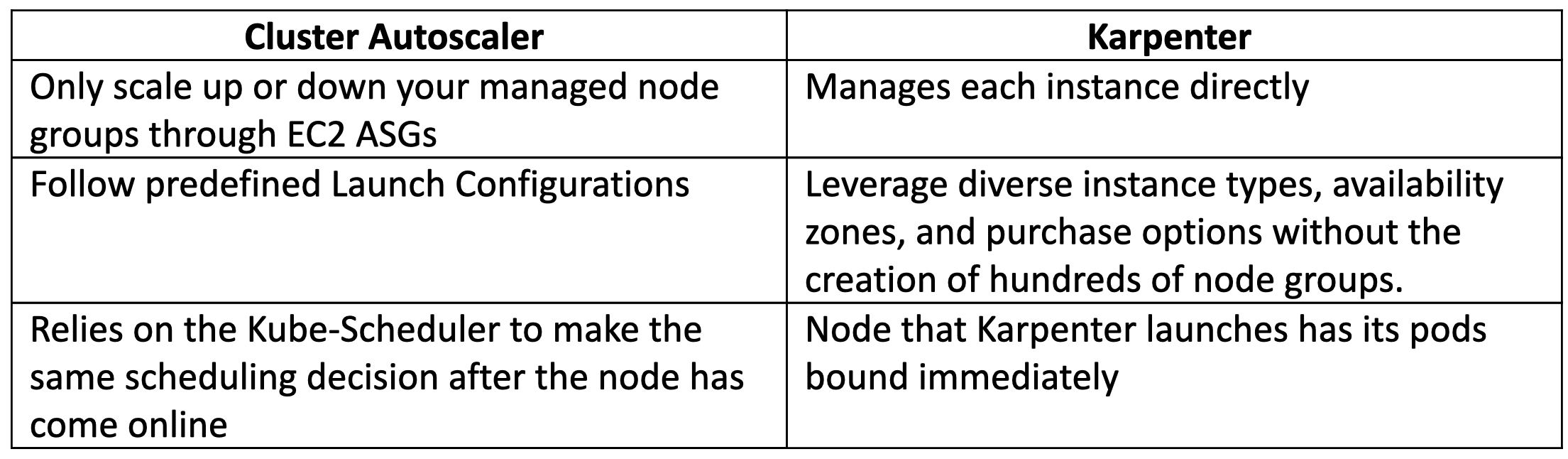
Below, we can see the following key differences between Cluster Autoscaler and Karpenter.
 Detailed Kubernetes Autoscaling guidelines from AWS can be found here.
Detailed Kubernetes Autoscaling guidelines from AWS can be found here.
Conclusion
To conclude, we can observe that when we inject some faults in the EKS cluster, Autoscaler (Karpenter) will perform an action to look at Kubernetes events/requests. We also notice that all these activities over the ArgoCD UI provide Node information as well as unscheduled pod information. So, to build a robust and fault-tolerant Kubernetes architecture, we can take advantage of the GitOps approach and perform chaos engineering to determine cluster capacity. In the next part of this blog, we will give a detailed explanation of Chaos Engineering.
Written By: Manish Soni & Suraj Solanki
