
Our experts are thinkers AND doers focused on accelerating business outcomes. To showcase our deep expertise, we created a blog series called “The Digital Build.”
YARN Node Labels:
Node label is a way to group nodes with similar characteristics and spark jobs can be specified where to run. With node labeling, we can achieve partition on the cluster, and by default, nodes belong to the DEFAULT partition.
Understanding EMR Node Types:
Master node: The master node manages the cluster and typically runs master components of distributed applications. All the major services like spark-history server, resource manager, and node manager runs on the master node.
Core node: A node with software components that run tasks and store data in the Hadoop Distributed File System (HDFS) on your cluster. Multi-node clusters have at least one core node.
Task node: A node with software components that only runs tasks and is utilized in adding power to perform parallel computation tasks on data, such as Hadoop MapReduce tasks and Spark executors. Task nodes don’t run the Data Node daemon, nor do they store data in HDFS.
Types of YARN node partitions:
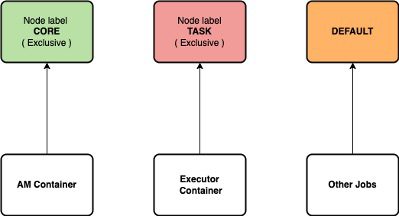
- Exclusive: Containers are allocated to nodes that exactly match node partitions. (e.g. Nodes requesting for CORE partition, are allocated to the node with partition=CORE. Nodes requesting DEFAULT partition, are allocated to DEFAULT partition nodes).
- Non-exclusive: If a partition is non-exclusive, it shares idle resources to the container requesting a DEFAULT partition.
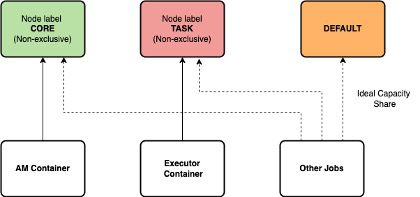
Non-Exclusive node partitions
Non-Exclusive node partitions
For example,
Consider two node labels,
- CORE -> For EMR core nodes
- TASK -> For EMR task nodes
First, register the node label list to the resource manager:
#Example for Non-exclusive node partitioning
yarn rmadmin -addToClusterNodeLabels "CORE(exclusive=false),TASK(exclusive=false)"
we can verify the node labels on the cluster using,
yarn cluster --list-node-labels
Note: Both commands cannot be run during the bootstrap action since, on EMR, the Hadoop installation takes place after bootstrap. This command can be run as a step after the cluster has been initialized.
YARN Node mapping Types:
- Centralized mapping
- Distributed mapping
- Delegated-Centralized mapping
Centralized YARN mapping:
Node to labels mapping can be done through Resource manager using API. Below is the code to register a node under the label on centralized mapping,
yarn rmadmin -replaceLabelsOnNode “node1[:port]=CORE node2=TASK” [-failOnUnknownNodes]
Same as the previous case, this cannot be included in bootstrap action. So the best delegate option would be the EMR default mapping configuration. (i.e. Distributed YARN mapping)
Distributed YARN mapping:
Node to labels mapping is set by a configured Node Labels Provider in Node manager. We have two different providers in YARN: Script-based provider and Configuration-based provider.
- In the case of script, Node manager can be configured with a script path and the script can emit the labels of the node.
- In the case of config, node Labels can be directly configured in the Node manager’s yarn-site.xml.
A dynamic refresh of the label mapping is supported in both of these options.
YARN site XML configuration (yarn-site.xml):
- Core node yarn configuration overwrite:
#Default configuration in EMR. yarn.node-labels.configuration-type="distributed" yarn.scheduler.capacity.root.default.default-node-label-expression="CORE" yarn.scheduler.capacity.root.accessible-node-labels="CORE,TASK" #Default false after EMR version 5.19.0 and later. yarn.node-labels.enabled="true" yarn.scheduler.capacity.root.default.accessible-node-labels="CORE,TASK"
- Task node yarn configuration overwrite:
#Default configuration in EMR. yarn.node-labels.configuration-type="distributed" yarn.scheduler.capacity.root.default.default-node-label-expression="TASK" yarn.scheduler.capacity.root.accessible-node-labels="CORE,TASK" #Default false after EMR version 5.19.0 and later. yarn.node-labels.enabled="true" yarn.scheduler.capacity.root.default.accessible-node-labels="CORE,TASK"
Capacity Scheduler Configuration:
Once the node labeling is configured, we need to assign a capacity percentage for each node label on capacity-scheduler.xml,
yarn.scheduler.capacity.root.accessible-node-labels.CORE.capacity="100" yarn.scheduler.capacity.root.accessible-node-labels.TASK.capacity="100" yarn.scheduler.capacity.root.default.accessible-node-labels.CORE.capacity="100" yarn.scheduler.capacity.root.default.accessible-node-labels.TASK.capacity="100" yarn.scheduler.capacity.root.accessible-node-labels="*" yarn.scheduler.capacity.root.default.accessible-node-labels="*"
After assigning node labels, we can verify the label status using the resource manager.
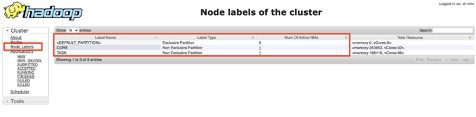
When launching a spark job, we can configure the driver and executor placement based on the node labels using the spark conf argument or by overwriting the spark default configuration file.
#Launches executor on TASK nodes --conf spark.yarn.executor.nodeLabelExpression="TASK" #Launches executor on CORE nodes --conf spark.yarn.am.nodeLabelExpression="CORE"
Use cases for node labeling:
- In most of the data engineering projects where EMR is used, SPOT instances are preferred for TASK nodes to reduce the overall cost but this brings the question about the stability of Spark jobs. When a Spark job is submitted to the EMR cluster, if the driver is launched in one of the task nodes and if that node is lost due to spot pricing fluctuation or any other reason, then the Spark jobs fail. To avoid such situations, the Yarn node labels play a major role in the driver and the executor placement across nodes when a spark job is launched with the cluster mode option.
- Some spark jobs might benefit from running on nodes with powerful CPUs. With YARN Node Labels, you can mark nodes with labels such as “MEMORY_NODES” (for nodes with more RAM) or “CPU_NODES” (for nodes with powerful CPUs) so that spark jobs can choose the nodes on which to run their containers. The YARN Resource Manager will schedule jobs based on those node labels.
Caveat on node labeling:
- When we configure the driver to always launch on the CORE node then the EMR concurrency is hugely dependent upon the size of the CORE node since more jobs can result in PENDING when capacity runs out.
- EMR ASG will be affected since there is no uniform allocation of the containers on CORE and TASK nodes.
Author: Vishal Periyasamy.
References:
- https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/NodeLabel.html
- https://ujjwalbhardwaj.me/post/ensuring-spark-launches-the-applicationmaster-on-an-on-demand-node-of-emr/
- https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-master-core-task-nodes.html
- https://medium.com/@sanjeevupreti/sharing-resources-in-emr-long-running-job-vs-small-jobs-c235ddb1aa75
