
Migrating billions of records
We had an interesting use case from a leading global tracking solutions provider to migrate billions of records from GPS tracking data.
This GPS tracking data was critical for the customer as they use it for important business analytics. They have around 2 billion records (as of March 2021) spread across 100s of databases, and nearly 1 lakh of tables (MySQL) & Amazon DynamoDB tables with more than 1.5TB of items. With the help of this data, they prepare several reports, perform analytical work, etc., and use them for their actual applications and software. Multiple storages like On-premises Data centers, Amazon RDS (Relational DB Services), Amazon DynamoDB, etc., contained their scattered Data. It was getting difficult since this increased their time and cost in getting proper reports from multiple sources. As they were scaling their business worldwide, it also impacts their business productivity in a huge way.
To solve this problem, it is necessary to consolidate the data from multiple sources into one master source. This data is greatly necessary for reports, analytics, etc.
How did we do it?
To consolidate the data, we had to perform several stages of data processing and data migrations. This came from multiple sources into a single master database in RDS Aurora MySQL. We took a step-by-step approach which involved the following migration scenarios:
- RDS to RDS Migration
- DynamoDB to RDS Migration
- Target Table Schema Changes
In this article, we will discuss in detail about our approach, challenges and the solution implemented for RDS-to-RDS Migration.
RDS-to-RDS Migration
The RDS data has spread across multiple databases and tables and gets difficult to prepare reports and manipulate data. This is because, they need to join different tables from different databases to get a detailed report for their applications.
Applying Data Transformation
Upon analysis, it was found that only certain attributes from specific tables and databases are needed for reporting. We had to perform data transformation and then migrate to a single table in the new target database.
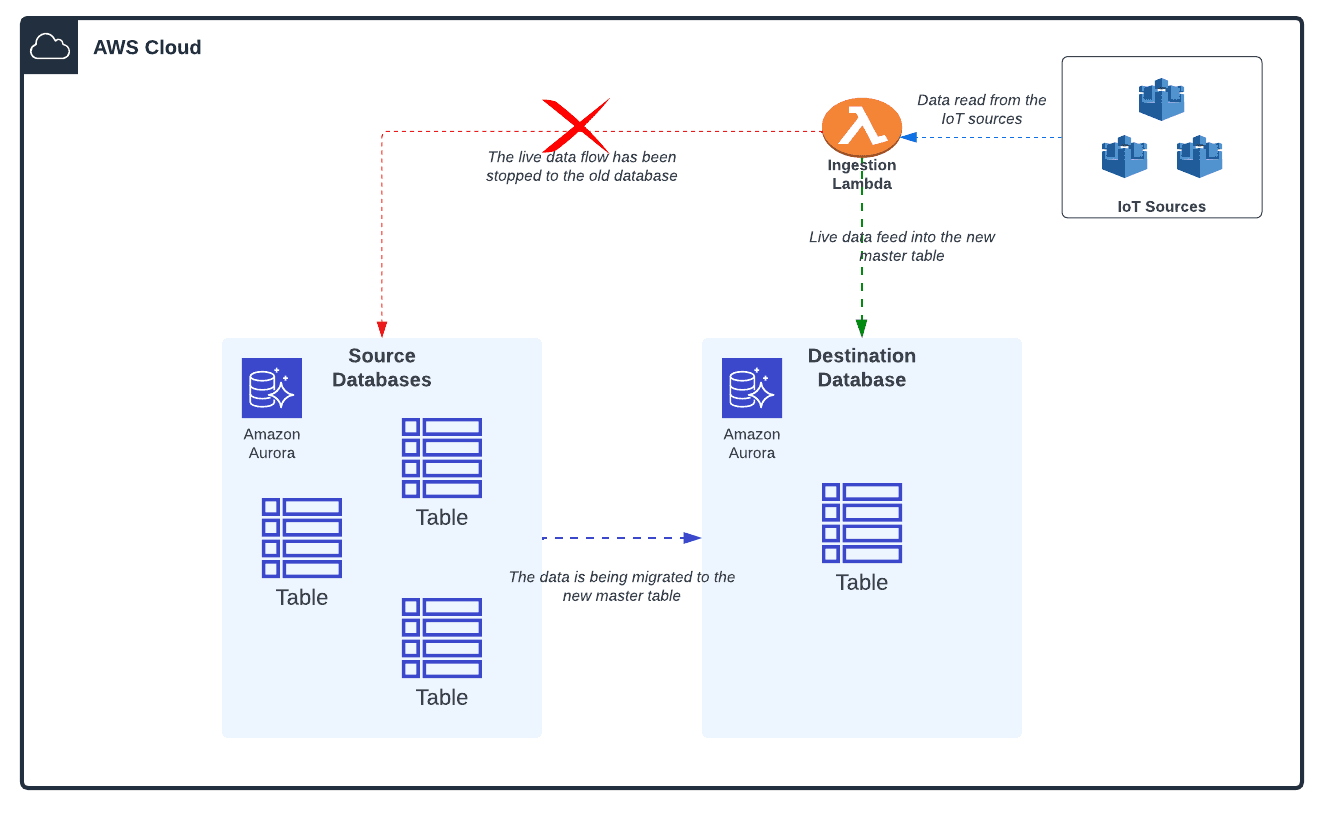
We will simultaneously push the new live data and migrate to the new database.
Output-table Schema:
There were nearly one hundred thousand tables in the source databases. Out of which, we picked forty to fifty columns, filtered and manipulated the values and assembled them in a single table as the final output. The schema of the output table has only forty-three columns that are most required for the application reports and analysis.
Some Factual Numbers:
| Total No of Tables | Total No of Records Migrated |
| 94562 | 927271108 |
Our Approach:
Initially, we had planned to fetch the required data, transform it, and export them into chunks of CSV (stored in AWS S3). Then, import them into a single table in the target database.
The Challenge:
The target table becomes locked for the entire import period. This makes it impossible to feed live data during the time.
We then took an alternative approach of extracting the data from the source table, transforming it and loading it directly. This is done with the help of EMR Spark through batch processing and also helps to overcome the table-lock issue.
Further Developments:
We decided to use Amazon EMR (Elastic MapReduce) Service to achieve our goal here.
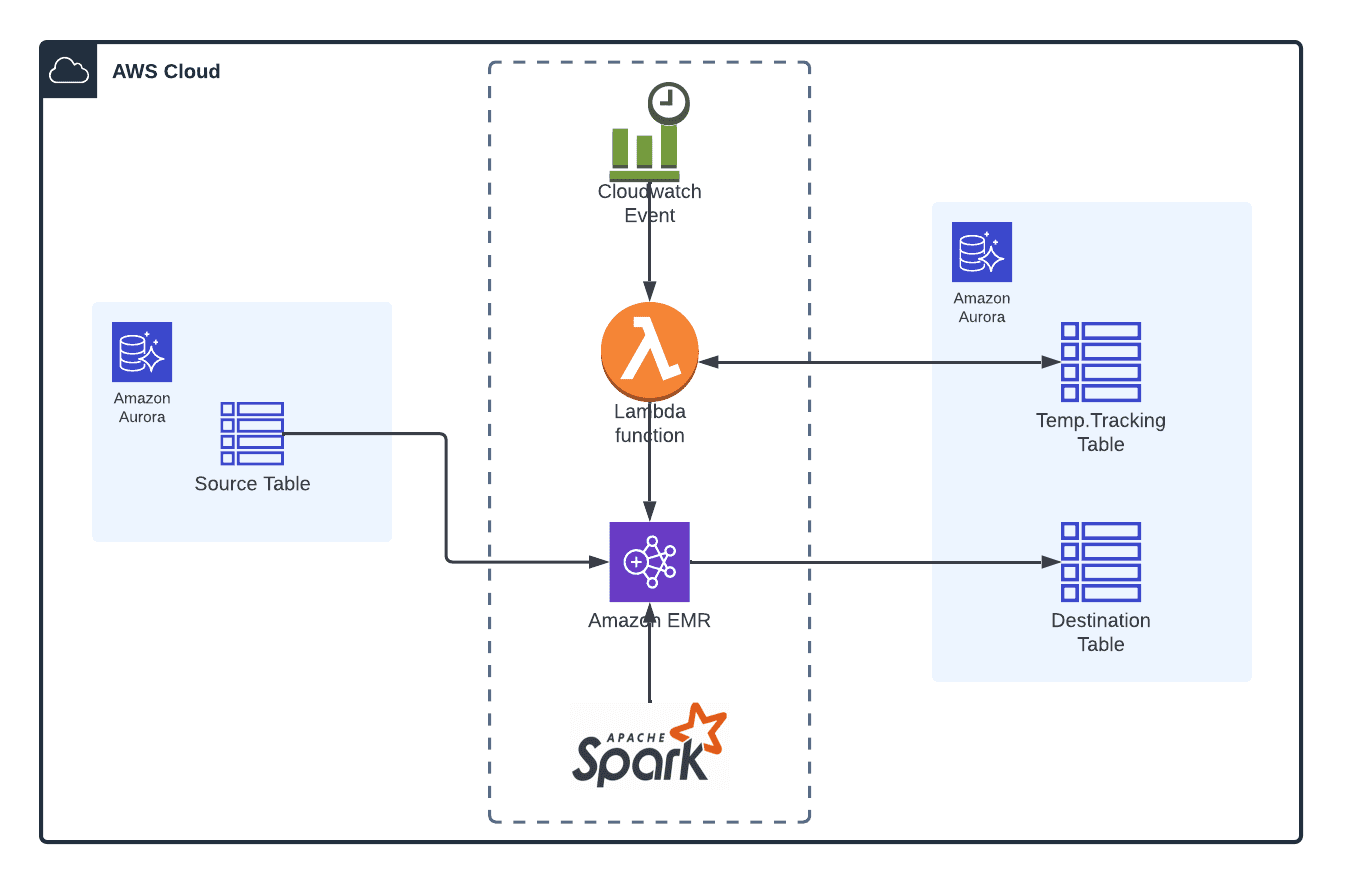
As shown in the above architecture diagram, we used the Amazon Lambda, AWS CloudWatch Event Rule, and AWS EMR services to work out this migration in a successful way.
AWS Service – Functionalities:
Each of those AWS services has a specific function to perform in the overall Migration process.
- AWS EMR: To extract the data from source tables, perform the transformation and then load the transformed data into the target database table.
- AWS CloudWatch Event Rule: To trigger the lambda function once in every two minutes.
- Amazon Lambda Function: To drive the migration process with the help of temporary tracking table.
- It reads the table or data that needs to be migrated from the temporary table and feeds that as input to the EMR Spark job.
- Once the given data is migrated by the EMR, lambda will update the details in the temporary table with the status.
Pre-requisites:
The deployment of the overall AWS resources in the environment was implemented using the Pulumi script. Important prerequisites to be implemented before the migration are:
- Target RDS-Database Setup:
- The new target DB must freshly created. This comes with a custom KMS key, parameter group, security group, VPC (Virtual Private Cloud), subnet, etc.
- Prepare the table schema with all the required attributes, data types, indexes, etc., to create the target table.
- Once the table is ready, repoint the live data streaming to it.
- Source RDS-Database Setup:
- Add the new reader instances in the existing source RDS cluster to support and handle countless read queries during the migration process.
Once they are in place, a temporary table was created in the target database to track the status of the data migration process. This table consists of the account id (which was fetched from the main source table to track the migration process based on that attribute), starting & ending timestamp, migration status, error indications, the time elapsed, no. of the total data that have been migrated so far, etc.
Migration Steps:
- Initially, the Event rule will trigger the lambda function. This will in turn read the account id and trigger the attribute value from the temporary tracking table. If the triggered value is 0 (means the migration is not triggered yet), it will feed the accountId as an input to the EMR Spark jobs. Else it will skip that account id.
- The Spark application fetches the required columns for which account id needs to be migrated to the target database.
- It will do transformations to those column values and load them into the target database table as batch processing.
- Each account id will have several thousands of rows in the source databases, so each will take several hours to complete the migration process.
- Once the migration of a particular account id is completed, the lambda will update the remaining columns in the temporary table.
The above process will be repeated for all the accountId till all the triggered columns become 1.
Challenges Involved:
- Charset Issue
- The Target table Charset/Collation is Latin1 which does not allow unknown characters. In one of the source tables, some “address” column has a Korean/Chinese value (Which is a data issue caused by google translate from lat and long)
- So, record insert will not be allowed in the target table, or it will be gibberish, check out the below address column:

- The challenge here is normal ALTER query will lock the whole table till it converts the required change, and with the table having Millions of records, there will be at-least 2hr downtime.
- To handle the challenge, Percona Toolkit is used for Modifying the Charset https://www.percona.com/doc/percona-toolkit/3.0/pt-online-schema-change.html which helps to alter the table without affecting the query process or table lock.
“CONVERT TO CHARACTER SET to utf8mb4 COLLATE utf8mb4_unicode_ci”
- Query-Bottleneck Issue
- A Join SQL statement is written between two different tables to extract the data.
- The query did not have a potential issue because it worked for the table having large data. But when we joined a smaller table than the parent table, it was slow.
- To get rid of this problem, we disabled the “block_nested_loop” parameter in the RDS parameters group.
- CPU Utilization Issue
- Aurora MySQL 5.6.22 cannot handle a heavy load of batch write requests, which reduces the performance of the running query.
- This is a known issue in MySQL 5.6 which was resolved in the later version.
(Ref) - Decreasing the number of threads or number of instances that process the data (A little Time Consuming).
- Aurora MySQL 5.6.22 cannot handle a heavy load of batch write requests, which reduces the performance of the running query.
How did we ensure Zero Data loss and Data Integrity?
For ensuring zero data loss, we compared the sum of the totalCount and the sum of the insertCount. If both are equal, then it was considered to be Zero data loss.
For data integrity, we generated a few sample reports for a particular period of time using old database tables and newly migrated database tables and tested with a few API calls and the results manually to make sure there are no differences between them.
Conclusion
This entire process helped the client to reduce their time in analysis, consolidate multiple data sources, and generate meaningful reports for better business outcomes. It took nearly a month of effort to build this solution and almost 80 hours of runtime to migrate more than 1.25 TB of data with nearly 1 billion records. It was a challenging task, considering the importance of the data.
In this article, we discussed in brief the RDS-to-RDS migration and in our upcoming article, we will discuss how we went ahead with DynamoDB to RDS migration and Target Table Schema Changes.
