
After completing the RDS-to-RDS migration, an additional column from DynamoDB needs to be added to the target table in RDS. We have also selected three additional columns to form a composite primary key. The data that needs to be migrated is spread across multiple storage systems, including RDS, DynamoDB, and on-premises data centers. The task now involves inserting the data into the target table in RDS by matching the records with the composite primary key. This means that the existing data in the target table will be updated with the new column value from DynamoDB while ensuring that the correct records are identified based on the composite primary key. This step completes the process of integrating the scattered data from various sources and consolidating it into the desired target table in RDS.
Proposed Solution
After a thorough brainstorming session, We have broken it down into pieces and devised a four-phase plan to fulfill the specified requirements.
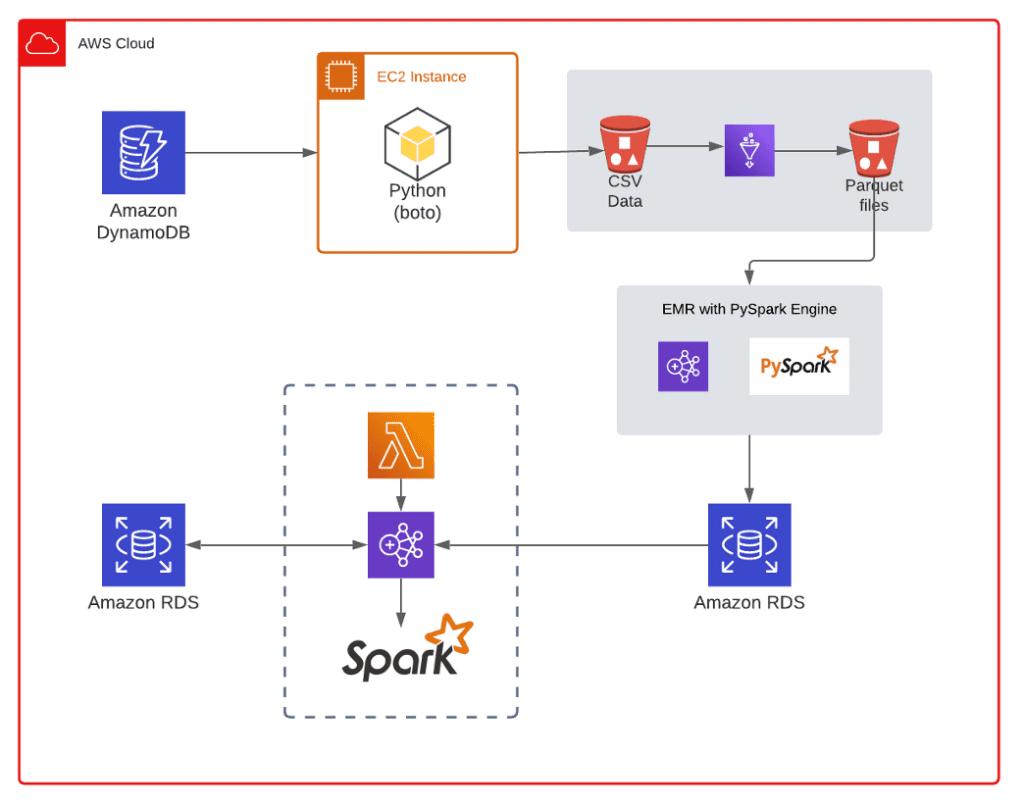
Phase 1: In this phase, we will use a Python script to read the data from the DynamoDB columns and write it to a CSV file. We will store this CSV file in an S3 bucket. This step allows you to extract the data from DynamoDB and make it available for further processing.
Phase 2: AWS (Amazon Web Services) Glue comes into play in this phase. We will use Glue to process the CSV files generated in Phase 1 and convert them into Parquet files. We will store the Parquet files in a separate location, either another S3 bucket or a different directory within the same bucket.
Phase 3: In this phase, we will utilize the PySpark engine running in AWS EMR (Elastic MapReduce). PySpark is a Python API (Application Programming Interface) for Apache Spark, a powerful distributed processing framework. We will use PySpark to read the Parquet files generated in Phase 2 and insert the data into an Amazon Aurora database. We will store the inserted data in a temporary table within Aurora. This step allows you to leverage the scalability and processing capabilities of EMR and PySpark for data transformation and loading.
Phase 4: In the final phase, we will perform the RDS to RDS migration process to insert the data from the temporary table in Amazon Aurora into the target table.
By breaking down the migration process into these four phases, we got a clear roadmap for migrating data from DynamoDB to an RDS database.
Challenges
- Enormous Data Volume: The first challenge is the sheer volume of data. With 2 billion records, extracting the required 8 months’ data can be time-consuming and resource-intensive. To perform this operation efficiently, a robust strategy for optimizing read operations is required.
- Live Data Ingestion: Both the source and target systems receive live data at about a million records per day. This poses a challenge as new data continues to flow into DynamoDB while the filtering operation is ongoing.
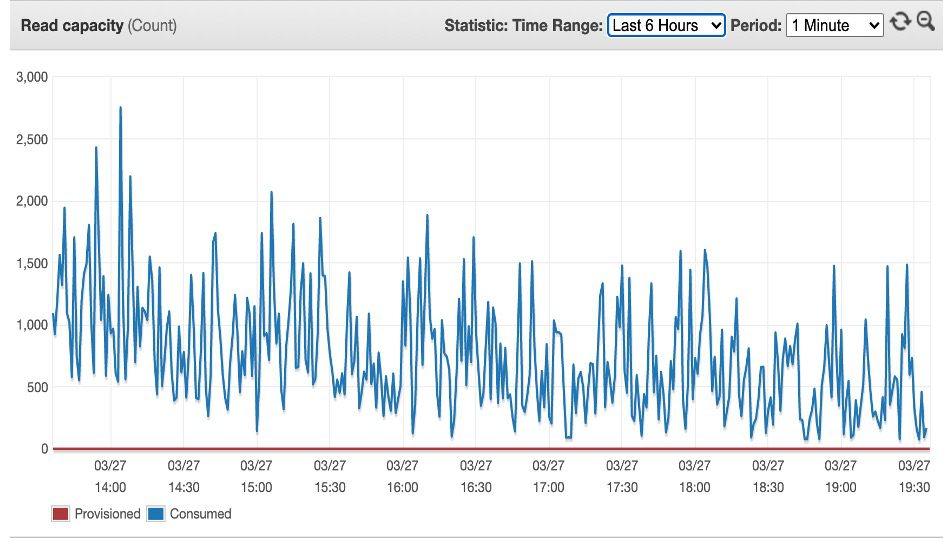
- Fluctuating Read Capacity Units: DynamoDB’s read capacity units (RCUs) determine the throughput for data retrieval. However, RCUs can vary over time due to changes in traffic patterns, leading to potential performance bottlenecks during the filtering process.
Stages
We have divided this use case into three parts for better management and execution.
- DynamoDB to S3: This involves migrating data from DynamoDB to an S3 bucket.
- S3 to Source TempTable: Next, we load the data from the S3 bucket into a source temporary table for further processing.
- Source TempTable to Master Table: The migration process concludes with the insertion of data from the source temporary table into the master table.
Implemented Approach
Stage 1: DynamoDB to S3
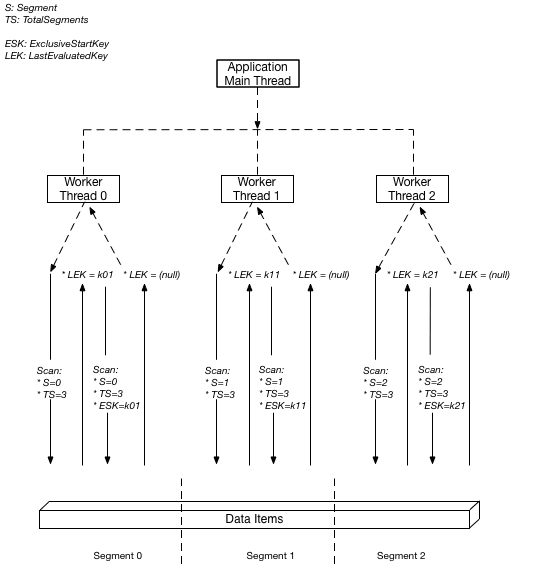
At the start of the process, we use a Python script that leverages multi-threading to query three columns from Amazon DynamoDB. We run this script on two parallel EC2 instances, each of which is a c4.2Xlarge. The script employs the DynamoDB segmented scan technique, which divides the data items into segments and assigns separate threads to process each segment. Each thread is responsible for fetching data within a one-hour period. Each thread then writes the fetched data to a CSV file in the output directory and logs any encountered errors in separate text files for each thread.
After running this process for a 30-day time limit on the EC2 instances, we upload all the generated output CSV files to an S3 bucket. After successfully pushing all the data to S3, we use AWS Glue to convert the CSV files into Parquet format. Parquet is an optimized columnar storage format that provides efficient compression and encoding, making it ideal for handling large datasets.
Stage 2: S3 to Source Temp Table
Next, we deploy AWS EMR with the PySpark engine to process the Parquet files. We read all the Parquet files and combine them into a single DataFrame. This DataFrame serves as the source for inserting the data into a temporary RDS Aurora MySQL table. After completing this step, we compare the data count in the RDS table to the data present in the Parquet files to ensure accuracy and consistency.
Stage 3: RDS Source Temp Table to RDS Target Table
Finally, we proceed with the RDS-to-RDS migration process, transferring the data from the temporary table to the target table in RDS. This migration finalizes the process, effectively consolidating the extracted, transformed, and loaded data from DynamoDB into the desired target table in RDS.
Ruled-out Approaches
- Using a Simple Python Script
- This approach, which relied on a simple Python script, also fell short as it resulted in unpredictable read capacity unit fluctuations. This made it difficult to estimate the time required for completion, and the estimated time limit was considered too long for the task.
- Using the Glue Job
- This approach involved using a glue job, but it proved to be unsuitable due to the fluctuating read capacity units, which made it challenging to gauge the execution time accurately. Furthermore, we estimated that this approach would be expensive.
Validation
- The validation process for the migrated data involved comparing the data count with the counts provided in the reports given by the client. We took this action to guarantee the precision and comprehensiveness of the migrated data.

Schema Changes
Requirement(s):
- To enhance the functionality of the migrated database, there is a need to introduce additional columns and modify the data type of the “Id” columns in multiple tables. We will specifically change the “Id” columns from INT(11) to BIGINT(13). This adjustment will facilitate improved data management and accommodate larger row identifiers. These updates will better equip the database to handle growing data volumes and support more robust operations.
Challenges:
- We insert about one million records into the live data on a daily basis.
- The tables are currently utilizing an older version of MySQL (5.6).
- It is necessary to perform an alteration to the table, which contains an estimated 2.5 billion records.

Schema Changes in the table01 Table
Some approaches were considered but not implemented, including:
- Direct Alter Query: This approach was not chosen because it can cause significant downtime during the alteration process, impacting the availability of the database.
- Schema Change Tools like Percona, Gh-ost, and Osc: While these tools allow online schema changes, they take a longer time than expected to execute due to the live data and triggers.
- We thought of creating a new table with the latest schema and migrating the data from the old table to this one. We explored the following options as potential solutions, but due to their time-consuming nature, we decided to exclude them all.
-
-
- AWS Data Pipeline
- AWS Database Migration Service
- EMR (PySpark Job)
- Direct Insert Query
-
Direct insert query using a multi-threaded Python script:
- This approach allows for the efficient insertion of large volumes of data into the database. By utilizing multiple threads, we can improve performance and reduce the time required for data insertion.
- The Multi-Threaded Python Script works by dividing the massive data insertion task into smaller, manageable chunks and then executing them concurrently using multiple threads. This parallel processing technique enables us to efficiently utilize the system’s resources, reducing overall processing time. Additionally, the script includes error-handling mechanisms and data validation to ensure a smooth and reliable alteration process.
Advantages of the Multi-Threaded Python Approach:
-
- Faster Execution: The script’s parallel processing nature allows for quicker data insertion, reducing the downtime associated with table alteration.
- Resource Optimization: By efficiently using the available system resources, the approach maximizes hardware utilization, resulting in a more cost-effective solution.
- Scalability: As your data grows, the Python script can easily scale to handle the increasing volume without compromising performance.
- Flexibility: You can tailor the script to meet specific business requirements, offering a high degree of flexibility and customization.
How did we make it work?
- Prior to running the script, it is essential to create a new table mirroring the old table, table01, and incorporating the updated schema.
- The script utilizes multi-threading programming to enhance its performance and efficiency.
- We need to copy data from a period of about three years.
- The script runs 30 times, handling each execution as follows:
- 30 days’ worth of data.
- Data for each thread is processed hourly.
- This results in a total of 720 threads per execution (30 days * 24 hours).
- Each thread is responsible for fetching data every second within an hour and inserting it into the newly created table.
Ensuring zero data loss
- We ensured the datatypes and columns in the table schema.
- With a Python script, we compared the data count for every second between the old table and the new table.
Time And Cost Estimation:
| Total No of Data | Total Time Taken |
| 2.5 billion (approx.) | 9 Days |
| Services & resources | Cost Calculation |
| AWS EC2 – m5.2xlarge – 2 Instances | $ 0.384 per Hour * 2 * 216 Hours = $ 165.888 |
Conclusion:
In conclusion, our data storage architecture underwent a significant transformation with the migration from DynamoDB to RDS and the schema changes on the RDS table. The need for a more versatile and relational database solution to accommodate evolving business requirements drove this endeavour. By embracing RDS, we have positioned ourselves for improved data management, streamlined reporting, and enhanced analytical capabilities. Overall, the transition to RDS and the associated schema changes mark a significant milestone in our data management strategy, fostering a more robust and efficient system for continued innovation and success.
