
In this blog, we delve into the fascinating realm of Retrieval-Augmented Generation (RAG) and its application with Azure OpenAI and LangChain. Discover how this innovative approach harnesses the power of pre-trained large language models (LLMs) to generate informative and human-like responses, enhancing real-world applications.
Retrieval-Augmented Generation (RAG)
This concept of RAG applied to large language models (LLMs) and vector databases (Vector DBs) is very similar to how a lawyer utilizes past judgments for a new case. Here’s the breakdown:
- Knowledge: The lawyer possesses a vast legal knowledge base gained through education and experience. This is similar to the LLM’s general knowledge acquired from its training data.
- Judgments (Vector DB): The lawyer retrieves relevant past judgments (documents) from a legal database. This is analogous to the Vector DB storing documents and their vector representations, which capture the semantic meaning.
The Case:
The client presents the lawyer with a new case (user query).
RAG in Action:
Retrieval (Similar to Lawyer Research): The user query is processed (similar to the lawyer understanding the case). We use techniques like vector search to find the Vector DB for documents (judgments) that are most relevant to the query (case). These documents become the retrieved passages.
Generation (Similar to Lawyer Argument): The LLM is presented with the user query and the retrieved passages (similar to the lawyer considering both the case and relevant past judgments). The LLM uses its knowledge and the context provided by the retrieved passages to generate a response (similar to the lawyer formulating an argument based on their knowledge and past cases).
Benefits (Like a Stronger Case):
- Accuracy: The retrieved passages provide factual grounding, reducing the LLM’s tendency towards “hallucinations” (making things up). This ensures a more accurate and relevant response, just like a lawyer’s argument is strengthened by relevant precedents.
- Efficiency: The LLM focuses on the retrieved passages, the most relevant information, instead of vast amounts of data. This improves efficiency, similar to how a lawyer doesn’t need to research every single law for a case.
Now that we understand the basics, let’s explore the technical details.
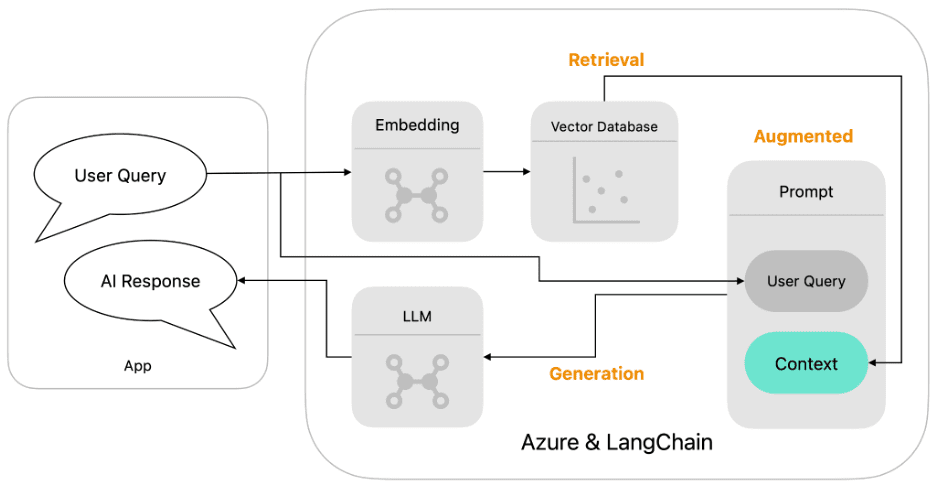
Tools:
- Azure OpenAI: This cutting-edge LLM from Microsoft is capable of generating human-quality text, making it ideal for the generation stage of the RAG pipeline. [Azure OpenAI]
- LangChain: This open-source library provides tools and components for building complex NLP pipelines, including the Agent feature, which facilitates conversation retrieval. [LangChain RAG]
- Azure AI Search: This cloud-based service acts as the “library” in our analogy. We’ll use it to store and search for relevant information based on user queries. [Azure AI Search]
Building the RAG System:
Here’s a step-by-step breakdown of the process:
1. Data Preparation:
-
- We’ll need a dataset of documents containing the knowledge base for our system. This could include FAQs, employee handbooks, policies and procedures documents, or any relevant corpus.
- Each document needs to be preprocessed and cleaned for better retrieval and generation.
2. Embedding and Indexing:
-
- We’ll employ the “text-embedding-3-large” model from Azure OpenAI to generate vector embeddings for each document in our dataset. These embeddings capture the semantic meaning of the text in a numerical format.
- We’ll then store these embeddings along with the corresponding documents in Azure AI Search. This effectively creates a searchable “library” of knowledge represented by vectors.
3. LangChain’s Retriever:
-
- LangChain’s Retriever feature helps build the retrieval component. It takes a user query and retrieves the most relevant documents from the Azure AI Search index based on a combination of vector similarity (using embeddings) and semantic similarity (using keyword matching).
4. Prompt Engineering and Generation:
-
- We’ll define prompts (templates) that guide the GPT model in generating responses. These prompts will incorporate the retrieved information.
- The GPT model will then use this prompt and its internal knowledge to generate a comprehensive response.
Sample Workbook:
# Python notebook scripts This setup will help you load the JSON file, ingest it into Azure AI Search, and use LangChain to query and generate responses based on the ingested data. To kickstart with loading JSON file and ingesting it into Azure AI Search, follow these steps: ## Import section ```python from langchain_community.document_loaders import JSONLoader from langchain_community.vectorstores.azuresearch import AzureSearch from langchain_openai import AzureOpenAIEmbeddings, AzureChatOpenAI from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain_core.prompts import ChatPromptTemplate from langchain.chains.combine_documents import create_stuff_documents_chain from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder from langchain_core.messages import HumanMessage from typing import Dict from langchain_core.runnables import RunnablePassthrough ``` ## Loader ```python loader = JSONLoader(file_path=, jq_schema=".[]", text_content=False) docs = loader.load() docs ``` ## Embedding ```python embeddings: AzureOpenAIEmbeddings = AzureOpenAIEmbeddings( azure_endpoint=openai_endpoint, api_key=openai_key, azure_deployment="text-embedding-3-large" ) ``` ## Vector store ```python vector_store: AzureSearch = AzureSearch( azure_search_endpoint=ai_search_endpoint, azure_search_key=ai_search_key, index_name=index_name, embedding_function=embeddings.embed_query ) ``` ## Processing the Bulk data into small chunks ```python text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200) split_docs = text_splitter.split_documents(docs) vector_store.add_documents(split_docs) docs = vector_store.hybrid_search( query="*", k=2, ) for d in docs: print(d.page_content) ``` ## LLM Configuration ```python llm = AzureChatOpenAI( azure_endpoint=os.environ["AZURE_OPENAI_ENDPOINT"], azure_deployment=os.environ["AZURE_OPENAI_DEPLOYMENT_NAME"], openai_api_version=os.environ["AZURE_OPENAI_API_VERSION"], ) ``` ## Converting the vector store into the retriever ```python retriever = vector_store.as_retriever() ``` ## Setting up the context ```python SYSTEM_TEMPLATE = """ Answer the user's questions based on the below context. If the context doesn't contain any relevant information to the question, don't make something up and just say "I don't know": {context} """ question_answering_prompt = ChatPromptTemplate.from_messages( [ ( "system", SYSTEM_TEMPLATE, ), MessagesPlaceholder(variable_name="messages"), ] ) ``` ## Chain configuration ```python document_chain = create_stuff_documents_chain(chat, question_answering_prompt) def parse_retriever_input(params: Dict): return params["messages"][-1].content retrieval_chain = RunnablePassthrough.assign( context=parse_retriever_input | retriever, ).assign( answer=document_chain, ) ``` ## Invoke the chain ```python retrieval_chain.invoke( { "messages": [ HumanMessage(content="What John Smith states from his experiment?") ], } ) ```Data Privacy and Security:
Powerful AI models without compromising confidentiality. This is a win-win for businesses with sensitive data.
Security and privacy are crucial in a Retrieval-Augmented Generation (RAG) implementation, particularly when it comes to handling and protecting data. Azure OpenAI Service, integrated with Azure’s comprehensive security framework, provides specific assurances that align with these needs.
Security Measures in Azure OpenAI Service for RAG Implementation:
1. Data Encryption
2. Access Controls
-
- Role-Based Access Control (RBAC)
- Azure Active Directory (AAD)
3. Network Security
-
- Virtual Networks (VNets)
- Private Endpoints
4. Compliance and Certifications
-
- Regulatory Compliance: Azure OpenAI Service complies with numerous regulatory standards like GDPR, HIPAA, ISO/IEC 27001, SOC 1/2/3, ensuring that data handling practices meet stringent regulatory requirements.
- Audit and Monitoring: Continuous monitoring and logging are in place to detect and respond to any security incidents.
Privacy Measures in Azure OpenAI Service for RAG Implementation:
- No Learning from Customer Data: Azure OpenAI Service has strict policies ensuring that customer data, including documents used in RAG implementations, is not used to train or improve the models. This is critical for maintaining the privacy and confidentiality of the data.
- Data Processing Agreements: These agreements outline how customer data is handled, processed, and protected, providing transparency and assurance regarding data usage.
What makes LangChain stand out?
LangChain helps RAG-based implementations work better with Azure OpenAI by giving a complete framework that combines parts for document storage, search, and text generation. It enhances workflow management, ensures data security and privacy, simplifies development and deployment, and optimizes performance, making it easier to build and maintain powerful RAG systems on Azure. Here’s how LangChain facilitates this process:
Hierarchical Indexing
This allows for efficient retrieval and better handling of large datasets. Hierarchical indexing breaks down the data into manageable chunks, improving the performance and accuracy of search queries. The indexing API lets you load and keep in sync documents from any source into a vector store. Specifically, it helps:
- Avoid writing duplicated content into the vector store
- Avoid re-writing unchanged content
- Avoid re-computing embeddings over unchanged content
For Azure environments, LangChain can be configured to work with Azure AI Search, which supports vector search capabilities. This integration makes it easy to work with embeddings made by LLMs and makes sure that relevant documents can be found quickly and correctly.
Retriever
It supports different types of retrievers, including BM25, dense retrieval (vector-based), and hybrid approaches. Custom retrievers can be implemented to leverage the specific capabilities of Azure AI Search, allowing for fine-tuned search and retrieval processes tailored to the application’s requirements.
Benefits
- Simplified Development: LangChain abstracts many complexities involved in building RAG-based applications, providing high-level interfaces and utilities.
- Flexibility: Developers can customize various components, such as retrievers and vector stores, to meet specific requirements.
- Scalability: Leveraging Azure’s cloud infrastructure, LangChain can scale to handle large datasets and high query volumes.
- Performance: Hierarchical indexing and efficient vector search integration ensure fast and accurate retrieval, enhancing the overall performance.
Real-World Applications:
Onboarding Assistant: Imagine a new employee joining a company. A RAG-powered assistant, built with this approach, can answer their questions about company policies and procedures in a natural, conversational manner. This not only streamlines onboarding but also fosters a more engaging experience for new hires.
Data Briefing Assistant: Researchers or analysts often face the challenge of quickly grasping key insights from large datasets. A RAG-based assistant can act as a valuable tool here. The assistant can provide briefings that are both clear and useful by getting relevant data summaries based on user queries and using the LLM’s ability to put together different pieces of information. This greatly speeds up the research process.
Conclusion
Using Retrieval-Augmented Generation (RAG) with Azure OpenAI and LangChain provides a robust framework for creating intelligent assistants that can give accurate, relevant, and natural responses. This method improves the precision and speed of large language models (LLMs) by putting them on a huge, already-processed knowledge base. This makes it less likely that they will come up with irrelevant or fabricated information. When you combine Azure AI Search for vector storage and retrieval with LangChain’s flexible retrieval mechanisms, you can make RAG implementations that are secure, scalable, and good for a wide range of real-world uses.
With Azure’s security measures, including encryption, role-based access, and compliance with regulations like GDPR and HIPAA, RAG systems can securely handle sensitive data, making them ideal for enterprise environments. LangChain further simplifies development, enabling rapid deployment and customization of RAG-based applications. This opens a lot of possibilities, from data briefing tools to onboarding assistants.
